现在处理数据文件常要遇到文件过大,动辄百万行数据,使用普通的文本编辑器基本上都打不开。在Linux中使用VI编辑器也要花很久才能打开,如果需要编辑这么大的文件就非常头痛。最近碰到一个问题,需要在一个40万行的数据文件中,抽出2万行最程序开发(开发阶段不需要那么完整的数据),于是找到了几种从大文件中抽取数据的方案。
统计文件行数
在开始抽取部分数据之前,我们需要知道整个文件有多少行。这个比较简单,可以使用以下命令:
wc -l data.txt
抽取前2万行数据
如果要抽取文件前2万行数据,简单使用以下命令:
head -n 20000 data.txt > 2w.txt
抽取后2万行数据
如果要抽取文件末尾2万行数据,简单使用以下命令:
tail -n 20000 data.txt > 2w.txt
抽取中间2万行数据
这回就比较难了,我们可以配合使用head和tail来处理。但是我觉得这个方法应该不算是最高效的。
head -n 80000 data.txt | tail -n 20000 > 2w.txt
以上命令将抽取第6万到8万中间的数据。命令的大致意思是先读取8万行,然后将结果通过管道传递给第二个指令,读取最后2万行数据,最后将结果保存在文件中。可以看出效率是非常低的。如果要读取第25万到26万行数据,岂不是要先读出26万行再截取最后2万行么?
head -n 260000 data.txt | tail -n 20000 > 2w.txt
当然如果整个数据文件一共30万行的话,我们也可以先读出后6万行,然后在读取结果的前2万行,也可以实现抽取25万、26万行数据:
tail -n 60000 data.txt | head -n 20000 > 2w.txt
从后往前读的方法不是特别推荐。如果一个文本可能有356200行的话,要读取25-26万行的数据,就先要计算从尾部读取多少万行,数学不太好就容易算错。
使用sed命令精准定位
当然我们可以使用另外一个命令精准地读取中间2万行数据,sed(Stream Editor文本流编辑工具)。该工具非常强大,这里我们就简单使用该工具读取24万和25万行数据。命令如下:
sed -n '260001q;240000,260000p' data.txt > 2w.txt
为了判断究竟哪一种方法更加高效,这边写了一个统计时间的脚本(该脚本的时间精度为纳秒级,只能在Linux或类似Git Bash,Cygwin上执行):
#!/bin/bash start=`date +%s%N` sed -n '260001q;240000,260000p' data.txt > 2w.txt end=`date +%s%N` echo sed:`expr $end - $start` nanoseconds. start=`date +%s%N` head -n 260000 data.txt | tail -n 20000 > 2w.txt end=`date +%s%N` echo head-tail:`expr $end - $start` nanoseconds.
经过测算,使用sed只需要657毫秒,而使用head和tail的组合需要725毫秒,比sed指令慢10%以上。
关于在sed中使用正则表达式
sed命令支持正则表达式的查找和替换,正则表达式中的通配符需要转义,例如:我需要替换一下文件中的id内容:
{"_id": "65d1d484d709e3030e6f05fb"}其中24位字符串是会动态变化的。所以使用以下方式替换,其中+和?:
sed 's/\"[a-z0-9]\+\"\}/\"65d1cbc9d709e3030e6edf31\"\}/' ../Beian.idx
如果需要直接在原文中查找替换,添加-i参数:
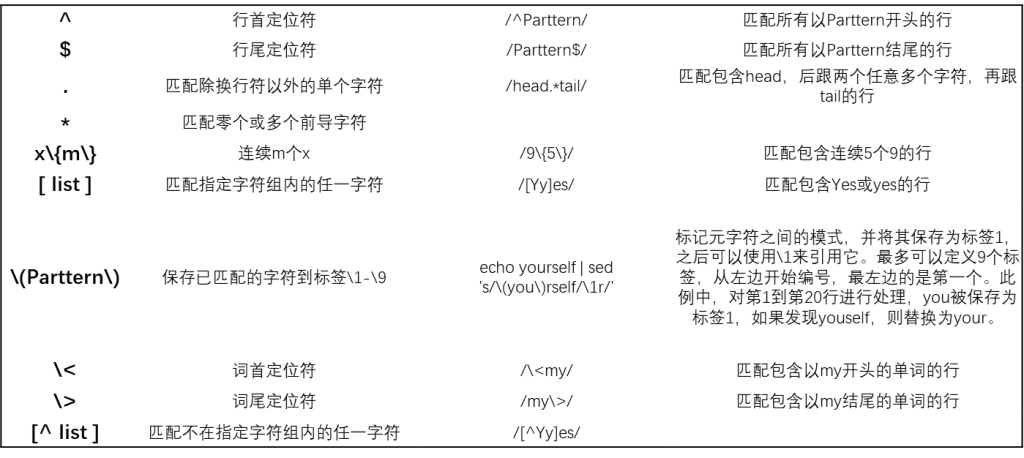
sed -i 's/\"[a-z0-9]\+\"\}/\"65d1cbc9d709e3030e6edf31\"\}/' ../Beian.idx以下是sed中支持的正则表达式的一些符号:

扫码联系船长