随着人工智能产业的日益火热,各种大大小小的科技公司都开始想方设法收集尽量多的数据已满足自适日益增长的数据需求。为了获取足够多的数据,科技公司开发了大量的爬虫工具尽可能地爬取能够访问的网站。其中图片网站,视频网站,新闻网站是其中最大的受害者。对于网站所有者来说,这些爬虫程序除了占用宝贵的带宽和服务器资源以外,没有带来任何利益。与此同时,由于贷款被占用,计算资源被消耗,最后影响到了真正的用户。本文将探讨集中比较常用的方法,侦测并识别爬虫行为。如果有必要,可以拒绝这类访问行为。
#1. 使用JS动态生成Cookie
这种方式是最简单的一个方案,用来屏蔽网络上90%的恶意爬虫。因为大多数的爬虫都是简单使用静态HTTP/HTTPS请求获得页面数据的。因此无法执行JS代码。这种方法首先在服务端检测Cookie的值,如果没有指定的值就返回一个JS保护页面。JS自动执行更新Cookie值以后再跳转回真正的内容页面。这个方法的优点是简单易用,防止大量简单高频的静态爬虫。
一般来说容易实现的反扒策略,被攻破也是相对容易的。这种情况只需要在配置一个Cookie在静态爬虫的HTTP头部信息,就可以轻而易举地绕过。为了增加难度,我们可以利用Session生成一个随机token和时间戳,并且用这两个参数做一个哈希值记录在Cookie中(Cookie仍然是通过JS生成,否则就无法起到轻易屏蔽静态爬虫的作用)。这样Cookie值包含了时间属性并且有过期时效,简单的复制粘贴就无法工作了。
#2. 使用JS动态生成访问密钥
这种方式同样是使用JS防止数据被爬取。相对第一种情况增加了难度。首先这个页面是动态渲染的,使用静态爬虫肯定是无法爬取到数据了。再次,由于是异步调用,即使使用静态爬虫模拟多次访问,首先要找到Ajax异步调用的访问密钥。由于这个密钥是动态生成的,并且在Session保留了原始密钥。这样恶意爬虫首先要找到这个异步调用,然后再找到异步调用中使用的密钥。由于这个密钥是JS动态创建的,就要找到对应的算法。
理论上这个方案只是增加了难度,并不能完全做到牢不可破。但是多增加一点难度,就多加一层数据安全保障。另外,为了防止访问密钥没有那么容易被发现,我们可以避免把密钥直接写在AJAX的访问链接上。之前有朋友研究某文书网的时候,死活找不到Ajax调用的URL中的访问密钥。从发起Ajax访问到最后的jQuery调用,访问地址都没有密钥的信息。但是在网络面板上就能看到一窜访问密钥。这个做法的好处就是加大了网站的爬取难度,使得数据更安全。
当然大家会问,Ajax访问密钥真的可以完全隐藏么?这个当然是不能的。只不过没有静态的写在Ajax调用前,而是在调用过程中加上的。至于怎么加更加隐蔽,大家可以思考一下XMLHttpRequest的几种状态。
#3. 检测浏览器防范Selenium自动化爬虫
好了既然有那么多JS问题,寻找加密算法耗时耗力,非常麻烦。很多恶意爬虫开发人员会直接使用Selenium,配合Webdriver和浏览器比如Chrome或者Firefox。这样通过浏览器自动完成了JS加解密,自动Ajax调用等。可能就是爬取速度慢了点。详情见《简介3种浏览器爬虫方案》。
对于这种方式,其实也是可以通过JS检测是否有Selenium的。通常情况下,通过Selenium启动的浏览器会在window对象中添加新的方法或者变量,我们只需要使用JS代码检测一下window对象是否有特殊的变量或者特殊的函数。例如可以检测一下变量值:
window.navigator.webdriver
对于不同版本的Webdriver和浏览器,检测的方法不同。附件为一个检测自动化Chrome的JS脚本。
chrome-headless-test
#4. 使用JS配合验证码
当前比较靠谱的验证码是滑动解锁。当前有好几种不同的滑动解锁方式,最简单的是爬动图片到缺失的背景缺口上,这种也最容易被破解。之前见过一个比较高大上的是百度的滑动解锁,通过滑动轴拖拽将小图旋转到匹配背景图的角度。另外还有一种就是按照给定的汉字顺序点击图片中旋转过的汉字,效果也非常好。还有一种验证码的方式是需要用户以短信方式发送一个验证码到一个指定号码,类似于微信的身份验证。
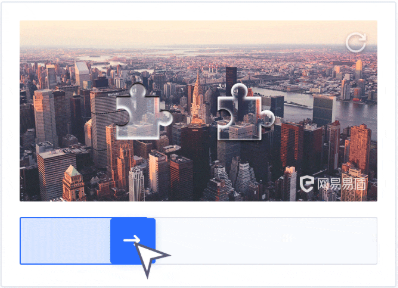
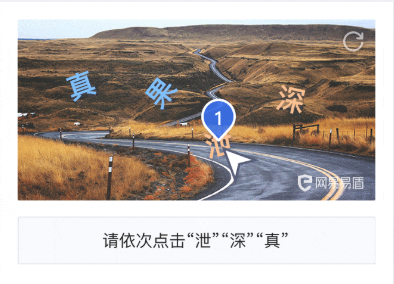
这类方法都是通过增加用户交互的方式,阻断自动化工具的工作流程。该类方案最大的问题不是验证码本身,而是在什么情况下跳出验证码。如果跳出的太频繁,就会影响正常用户体验;如果不够敏感,就没有办法保护数据。因此在度的拿捏上要斟酌。另外一个问题是通过什么途径标识恶意用户,使用Cookie标识或是记录IP地址,又或者是通过用户浏览器UA标识。更多关于标识恶意用户的参数可以参考fingerprint2。
#5. 通过账号保护
这种方案只对于特定的服务数据有效。例如新闻类网站就不适合了。简单说来就是要访问数据就要先登录。每次访问都会留下访问记录,根据访问频率和数量可以判断是否是爬虫行为,如果是就直接封号。比如天眼查的搜索服务,如果搜索次数过多,就会跳出用户登陆界面。用户登陆以后,还会在结合JS验证码方式降低访问频率。这种方式的优点在于可以高效地防止自动化数据采集,同时在保证服务质量地情况下为真实用户更好地提供服务。
#7. 毒数据
此方法不同于之前几种方法之处在于,之前的几种方法都是通过阻止自动化工具采集数据。而这种方法是在成功标识出恶意访问后提供伪造数据。从自动化工具的角度看,数据是可以成功采集的,并且很难在大量数据中发现哪些是假数据,哪些是真数据。这种方式比较有效地限制了采集工具的升级迭代,有效地保护了数据。该方法的挑战只要是如何识别自动化采集工具,并且如何高效的提供假数据,并让假数据看起来没有问题。
#8. 不提供网页版本
相比网页数据,手机端APP数据爬取难度要大很多。首先,相比于网页版服务,手机端APP的数据通信不容易被分析。由于当前手机系统普遍强制使用HTTPS,因此如果不做特殊处理的话,使用普通的数据包分析工具是无法分析出数据包的内容的。另外,使用手机端APP使用通信加密更加方便。举个例子,在网页端进现数据加密,JS代码是明文的(即使混淆),只要耐心分析JS代码都能找到加密方法。但是APP是一个打包的执行文件。如果需要分析源代码,就需要反编译APP应用,难度大很多。如果不分析数据流,而是直接通过自动化工具操作,可能会遇到相比网页版采集工具更加复杂的工作流程,在复杂度和成本上都增加了不小的难度。