在开始写M3U8流视频数据爬虫教程的时候,本打算只写一篇文章。在文章《M3U8流视频数据爬虫详解一:M3U8视频文件详解》中,我们详细描述了M3U文件的定义和M3U8文件的详细结构,并且给出了实际样例。在写作和编辑后期,我们逐步发现有很多细节还是不能省略的。但是如果教程太长,就不利于读者对于内容的理解和吸收。最后决定把“M3U8流视频数据爬虫”分为三个部分完成。第一部分就是之前的《M3U8视频文件详解》。第二部分就是本文,将主要覆盖Chrome浏览器分析工具介绍,流视频数据源的网页分析,爬虫设计。本系列教程的最终目标是,读者经过学习以后,能够独立地从数据源分析到完成数据爬虫程序编写。
在开始之前,我们先介绍一下开发M3U8视频爬虫的总体思路与方法。一般而言,在我们着手编写数据爬虫之前,必须先确认数据源,随后使用网络流量监测工具例如Chrome/Firefox浏览器开发者工具,或者Fiddler网络数据包分析工具分析数据源的具体网络数据包信息。在此基础上,通过Python脚本编写爬虫代码。为了能够更加有效的讲解和分析,本教程就选用阿里大学的教学视频作为数据源进行学习和分析。因此,如本文涉及到数据版权问题,网络安全问题等,可以及时联系我们。
Chrome浏览器分析工具介绍
在本教程中将使用Chrome浏览器开发工具(Chrome Developer Tools)。主要原因还是Chrome浏览器分析工具提供了全面的分析工具,即可以分析页面代码,调试JS脚本,监控网络流量和数据包分析。当然,如果读者对Firefox情有独钟,对firebug(火狐浏览器的开发者工具)非常熟悉,也是可以使用的。
Fiddler也是非常强大的网络数据监控和调试工具。但是由于没有和浏览器深度整合,不具备JS调用,分析页面源代码也不方便。然而,不用Fiddler最主要的问题是,现在众多网站使用的是HTTPS,因此如果要分析HTTPS数据包,需要配置证书。而浏览器开发工具是不需要的。
当我们打开Chrome浏览器以后,可以使用F12快捷键激活开发工具。以下是Chrome浏览器开发工具的一个截图(网络选项卡)。该截图是在监控阿里大学视频教学页面的网络数据包,并且在图中标出了我们需要通过Python脚本下载的几个重要文件。其中包括m3u8一级文件,m3u8二级文件,密钥文件(key文件)和ts视频文件。

分析和下载M3U8文件
分析页面数据在开发网络爬虫的整个流程中是非常重要的一部分(个人认为是最重要的一部分)。我们只有在分析了目标数据源是如何载入数据的基础上,才能正确地设计和编写网络爬虫。本章节将详细讲述如何分析页面数据,并在浏览器的开发者工具中找到目标数据,并分析数据的内容。下面我们就以《0基础入门学Python》的第一个是视频教程为例,详细的展开介绍如何使用Chrome开发者工具分析页面和数据包。有兴趣的读者可以打开这个路径自己试一下:
https://edu.aliyun.com/lesson_137_1545#_1545
激活和查看网络数据
在Chrome浏览器中打开以上网址,并在当前页面使用快捷键F12打开开发者工具。开发者工具出现以后,请选择上方的Network选项卡。在Network窗口勾选“Preserve Log”选项,随后点击左上方红色方块旁边的Clear按钮清除当前网络数据记录。最后在网页中按F5刷新页面。此时,在开发者工具的Network界面就会出现该页面对应的完整的网络流量记录。如下图所示:
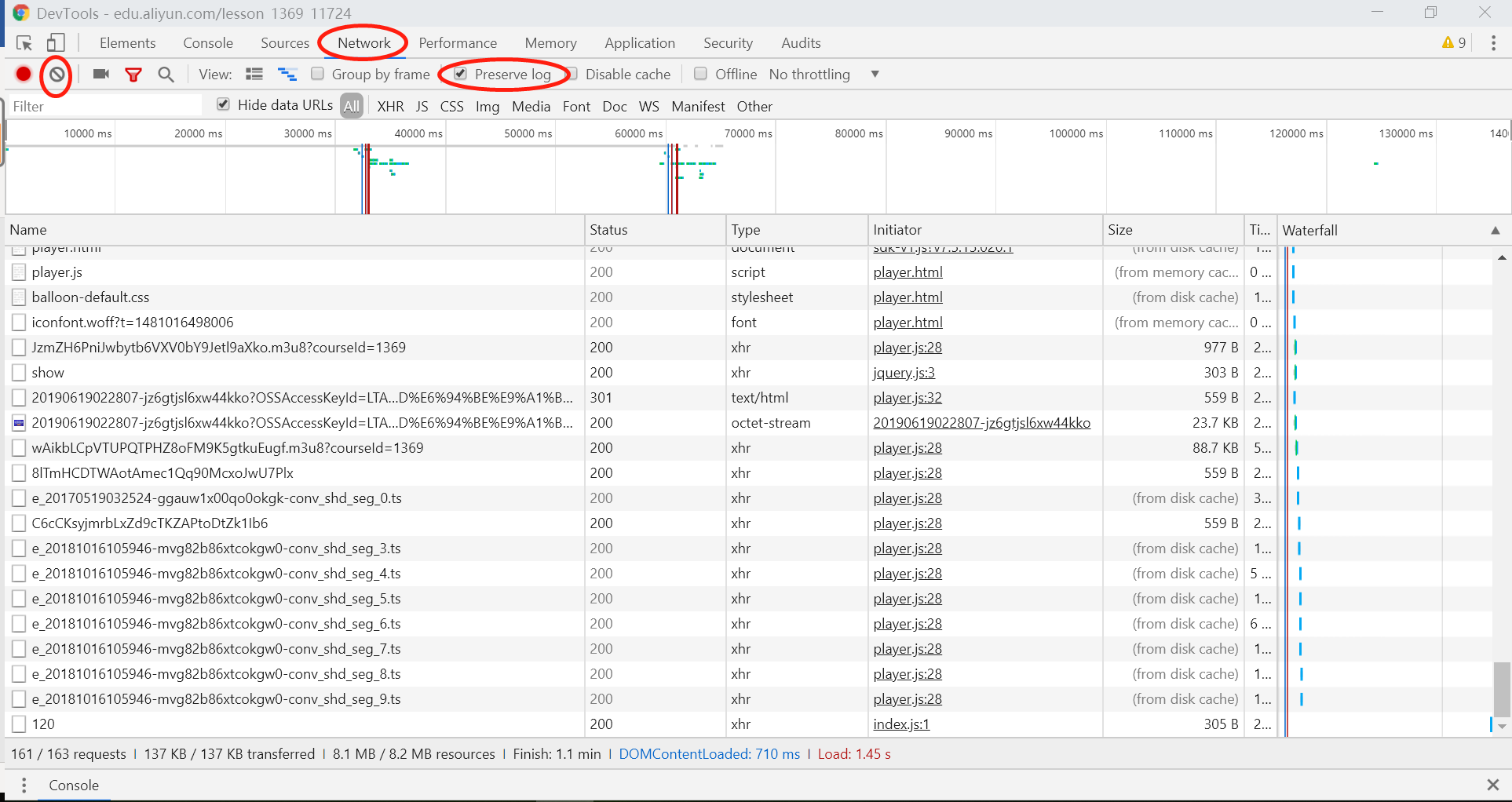
分析网络数据包
接下来我们从得到的网络数据记录中进行分析。首先我们将滚动条拉到最底端,可以看到几个以.ts为后缀名的文件。我们在文章《M3U8流视频数据爬虫详解一:M3U8视频文件详解》中讲过,这个就是实际的视频文件(可能被加密)。当TS文件在网络数据列表中出现,说明这个时候m3u8文件已经被浏览器下载并解析了。如图所示,我们在网络数据中找到了两个m3u8文件。 分别为:
TH4MhARjFkLDvg8PYJ4ZUsO3RlMXSLDW.m3u8?courseId=1369 fHj2h8B7jOM3z5fIgI2QN6XdBHnKpfNF.m3u8?courseId=1369
注意:阿里云对视频链接地址做了保护,所有的视频地址只能访问一次。由于以上两个视频链接已经被浏览器访问了,所以我们拷贝出来再次访问将出现404的错误。这个是阿里自己研发的视频保护方案。在大家自己动手做项目实验的时候,建议使用浏览器没有播放的视频文件。例如,大家在浏览器调试时,播放的是高清视频的链接地址。那我们在代码中使用标清视频的链接,反之亦然。
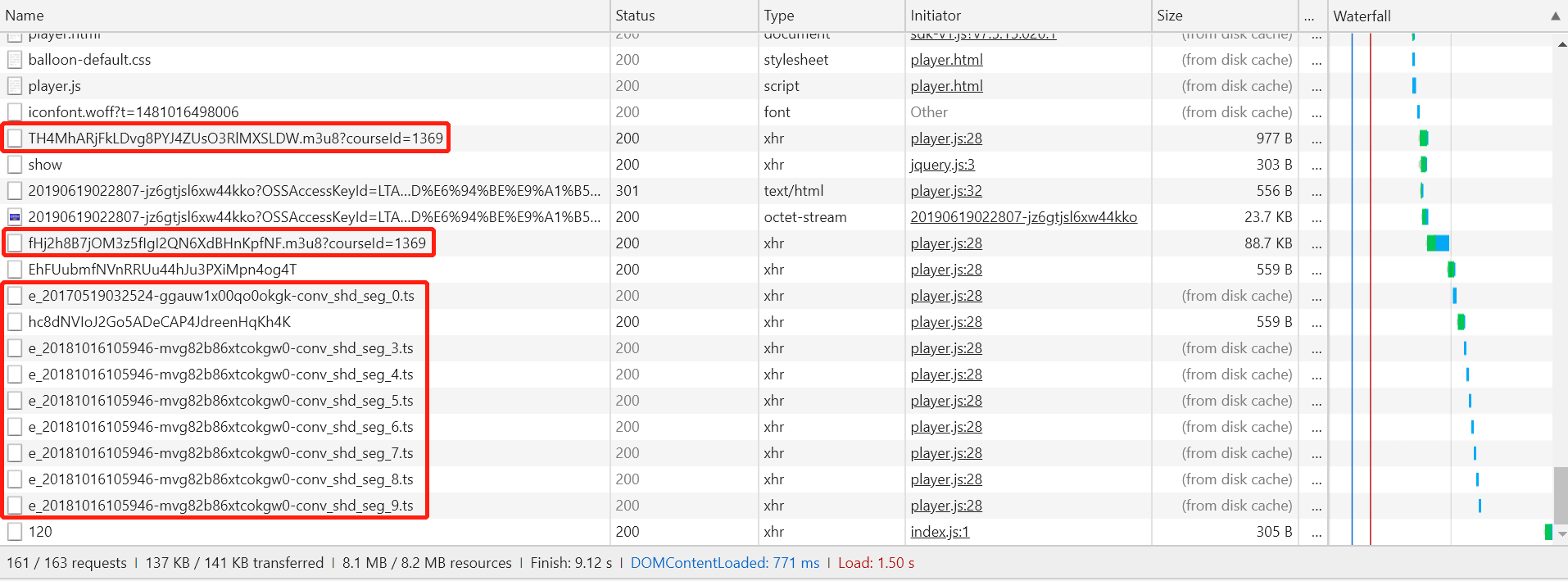
由于m3u8文件最多只能有两级,所以我们可以推测第一个为一级文件,第二个为二级文件。接下来我们可以确认一下此推测是否准确。首先鼠标左键点击第一个M3U8文件数据记录。在开发者工具的网络窗口右侧会出现该数据的详细信息。如图所示:

在“Preview”窗口我们可以看到该数据包的内容。其中包含了为三个不同的网络带宽提供的三个不同版本的M3U8文件。并且第三个M3U8文件连接地址,正是Chrome开发者工具网络数据记录中的第二条M3U8文件的HTTP数据。
接下来我们再来看看第二条M3U8文件的数据内容。同样使用鼠标左键点击第二个M3U8文件数据记录。在开发者工具的网络窗口右侧会出现该数据的详细信息。如图所示:

同样在“Preview”窗口我们可以看到该数据包的内容。而且内容中包含的TS文件列表的URL记录正是开发者工具的网络窗口最后出现的TS网络数据记录。
分析总结
基于以上对一个视频页面的网络数据记录分析得出,该播放页面首先会下载一个一级M3U8文件,该文件中保存了三个不同版本(不同的视频,个数可能不同)的二级M3U8文件。每一个二级M3U8文件中都包含了若干(几十个到上百个)TS视频URL地址。通过给出的TS视频URL地址下载到真正的TS视频文件,解密后播放。
这里有一点需要特别指出:阿里云的后端设计巧妙,所有的M3U8文件URL地址(无论一级或者二级),所有的Key的密钥URL地址,所有的TS视频文件URL地址,都只能访问一次。再次访问以后,都会出现404页面无法访问。因此,只要在Chrome开发者工具的网络窗口出现过的URL,再次访问都是无法访问的。因此,在后期开发爬虫的过程中一定要注意这个问题。所有的URL只能访问(爬取)一次。
另外,访问阿里大学的视频是需要事先登陆的。为了简化爬虫的复杂性,我们可以先在Chrome浏览器中登陆以后,再分析数据包。再开发爬虫或者爬取数据之前,我们只需要拷贝HTTP数据头信息Cookie,User-Agent和Referer等信息就可以绕过登陆限制。具体操作会在后面的章节中详细描述。
阿里大学教学视频的爬虫设计思路
根据以上分析,我们可以初步得出一个教学视频的爬虫设计思路:
- 浏览器中登陆,为后面数据爬取做准备
- 获取一级M3U8文件URL
- 下载一级M3U8文件并保存到本地
- 解析一级M3U8文件,获取不同带宽对应的二级M3U8文件URL
- 下载二级M3U8文件并保存到本地
- 解析二级M3U8文件中的密钥(Key)URL,对应的IV值,对应的TS文件URL
- 下载密钥(Key)文件,记录IV值
- 下载TS文件,并保存到本地
本爬虫的设计思路基本上是适合大部分的M3U8视频网站的。基于具体的网站,还是需要按照上节中的步骤分析,对于具体的情况适当修改当前设计思路即可。在本示例中,阿里大学的视频主要有以下特点:
- 页面需要登陆,因此需要拷贝HTTP数据头信息绕过登陆限制
- 所有重要URL只能访问一次,第二次访问就出现404页面
- 二级M3U8文件中,每一个条TS文件都有对应的Key和IV值,因此必须一对一记录和保存
在下一篇文章中,我们将根据以上的设计思路来一步一步实现数据爬虫程序。