最近关注股票和基金的朋友比较多,可能是由于股市表现和基金走势都非常好,所有关注基金的朋友也越来越多。每年的一月份都是个大基金公司披露四季报和年报的时间点。所以有朋友托我看看能不能帮助分析一下上市基金的四季报。目前的情况是有一堆的PDF类型的公告,如何把这些基金公告转换成Excel的数据表,这样就方便统计和分析了。市场上PDF解析工具非常多,也有很多项目支持PDF的表格解析。于是,本人就挑选了一个比较有知名度第三方工具:pdfplumber。
pdfplumber是基于pdfminer的,但是提供了更高层的功能接口和抽象表现。尤其是在表格抽取方面,算是市面上表现最好的PDF解析库。因此,我就先拿一个“鹏华沪深300指数基金四季报”尝试一下pdfplumber解析PDF的综合能力。首先我们看公告第一页的内容如下:

首先我们先看看pdfplumber默认的解析效果:
import pdfplumber
pdf = pdfplumber.open("sample/table.pdf")
for page in pdf.pages:
print(page.extract_text())
通过以上代码,输出在屏幕上的效果还是不错的,每一段的内容大致都没有问题,最底下的表格中每一个单元格的内容看似还都可以。如图所示:

接下来就要想办法用pdfplumber导出PDF的表格了。首先,我们要稍微改造一下代码。
import pdfplumber
import xlwt
book = xlwt.Workbook(encoding="utf-8", style_compression=0)
sheet = book.add_sheet("report", cell_overwrite_ok=True)
pdf = pdfplumber.open("sample/table.pdf")
page1 = pdf.pages[1]
tables = page1.extract_tables()
table = tables[0]
for rowIndex in range(len(table)):
row = table[rowIndex]
for colIndex in range(len(row)):
cell = row[colIndex]
sheet.write(rowIndex, colIndex, cell)
book.save("sample.xls")
这里代码稍微复杂了一些,主要是因为我们使用了xlwt库,用来把PDF中提取的表格保存到Excel文件中。代码运行以后在Excel中的样例数据如下:

如图所示,pdfplumber如实地提取了PDF文件中的表格,但是也能发现一些问题。比如,右边单元格中的成段的内容,每一行都被理解成了一段。因此在单元格中,每一行不会自动拼接起来。
pdfplumber解析表格遇到的问题
目前经过多个PDF的测试,发现pdfplumber只能解析表格完美被线框包裹的情况,如上节中的测试样例。但是对于各种上市公司公告,基金公告中存在的表格,并不是标准的。本文中的样例“鹏华沪深300指数基金四季报”算是相当标准的PDF文档,其中的表格也是非常标准的。但是在如此完美的标准PDF中,仍然需要进行精确的校准。以下是我们在各种公告中遇到的一些问题,后期也会根据不同的问题给出不同的解决方案。
- 问题1: 表格中单元格中数据被理解成段落。在Excel中不能自动换行。
- 问题2: PDF原文中表格分页,导致pdfplumber在不同页面上识别出两个不同表格,需要在代码中逻辑合并。但是使用什么条件来判断表格被拆分成了两页是一个问题。
- 问题3: 表头中的换行别识别为表格中的多行。
- 问题4: 一张长表分布在不同的页中,每页的表都有表头。样例“北京市博汇科技发行公告”中第10、11页。
- 问题5: 表格第一行缺横线,导致第一行丢失问题。样例“长信利众 : 2020年第四季度报告”中第14页。
- 问题6: 表格缺竖线,导致整个列的数据都识别不出来。样例“关于分拆所属子公司厦门厦钨新能源材料有限公司至科创板上市的预案”中第3页的表格。

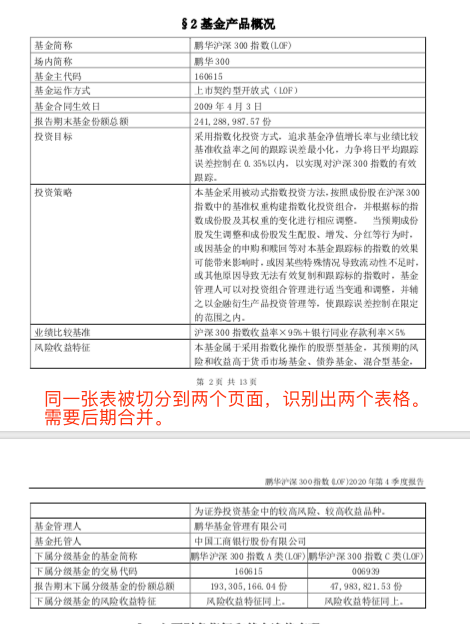
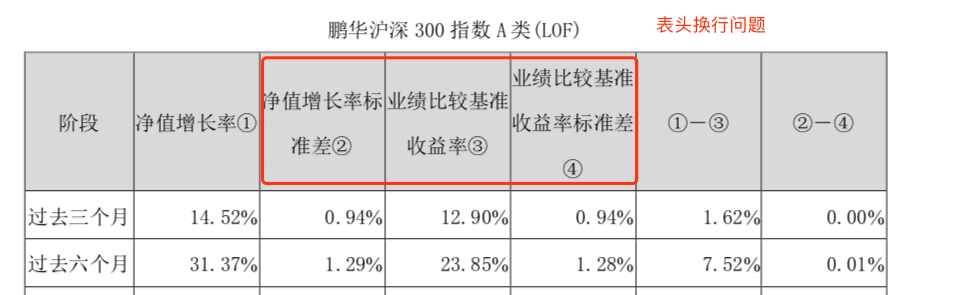
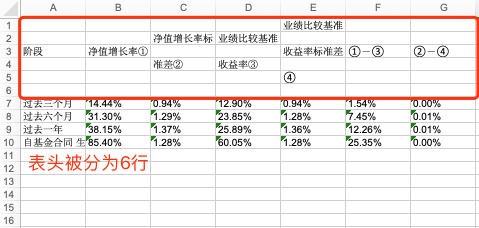


如果使用默认的表格配置强行解析识别,大概率的结果是这样的:

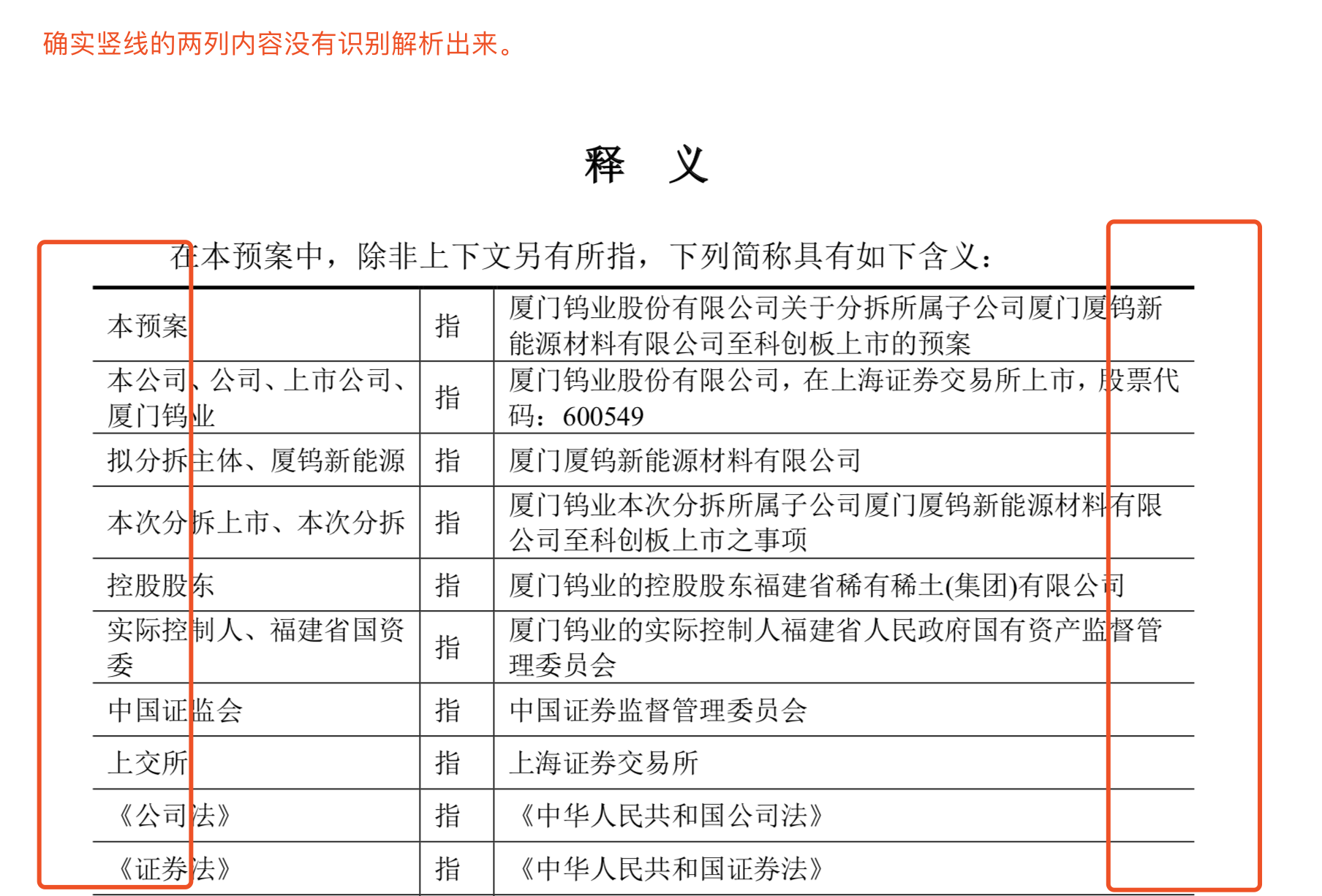
如果使用默认的表格配置强行解析识别,大概率的结果是这样的:
对于以上每一种问题,并不是非常难解决的。因为可以对于没一种问题写特殊的代码强型处理一下最终的数据字段。但是最大的难点在于,如何在代码中自动识别当前表格解析出现问题。从输入输出的角度讲,我们的输入是完整的pdf文件,我们也不知道pdf文件中是不是真有表格,表格应该是几行,是否缺了。如果无法在代码中自动识别问题,就无法自动修复问题。那么就无法搭建一个通用的PDF表格识别工具。