模版定位及规则编写。
以下是第一层字段:
- url:目标页面URL
- section:板块的URL。默认情况下和板块URL一样。例外情况比如板块页面使用ajax获取数据,url可能是ajax的URL。
- news_source:网站-板块-子版块A-子版块B
- version:默认值为0.0.1
- plan_id:默认值为null
- charset:板块列表页的编码。默认值为null,如果使用默认值则依靠requests自动检测。
- seleniumflag:默认值为null
- itemURLReg:详情页URL规则
- itemDateReg:详情页时间规则
- paginationURLReg:模版列表页翻页规则
- item:详情页规则集合
itemURLReg详情页URL规则的字段定义:
- type:规则类型,支持的值为xpath或者regex。
- format:默认值为null。当url不规则时给定需要格式化的表达式,目前已经弃用。
- value:具体规则表达式。当type为regex时,需要精确到url字符串;当type为xpath时,精确到a标签即可。
样例如下:
"itemURLReg": {
"type": "xpath",
"value": "//div[@class='newsItems']/a",
"format": null
}
itemDateReg列表页中详情的时间提取规则字段定义:
- type:规则类型,支持的值为xpath或者regex;当列表页没有时间属性时,设为null;此时无法通过是设置时间范围全量爬取,在自动定时爬取任务过程中,通过判断去重全量爬取。
- format:时间在页面上的格式,用来把字符串时间转化为时间对象。
- value:具体规则表达式。当type为regex时,需要精确到时间字符串;当type为xpath时,精确到时间标签即可。
样例1,时间在页面上的格式为“2021-03-14”:
"itemDateReg": {
"type": "xpath",
"format": "%Y-%m-%d",
"value": "//li/em"
}
样例2,时间在页面上的格式为“2021年03月14日 08:45”:
"itemDateReg": {
"value": "\\d{4}年\\d{2}月\\d{2}日 \\d{2}:\\d{2}",
"type":"regex",
"format": "%Y年%m月%d日 %H:%M"
}
paginationURLReg翻页规则中的字段定义:
- type:规则类型,支持的值为auto-increase或者selenium。
- format:当type为auto-increase时可用。翻页URL的字符串模版。
- value:当type为auto-increase时可用。该值将被format格式化为第一次翻页的URL。
- step:当type为auto-increase时可用。该值为翻页累加值,将被format格式化为翻页的URL。
item详情页规则集合中的字段定义:
- plugin:使用plugin解析详情页面。目前只支持selenium。默认值为null。
- actions:plugin需要处理的操作,需要和plugin配合使用。默认值为null。
- charset:详情页编码。有时详情页编码和列表页不同,且requests无法自动检测。默认值为null。
- fields:详情页规则集合。
fields中详情页提取规则字段定义:
- type:提取规则的类型。目前只支持xpath。
- value:具体规则表达式,必须精确到text()
- field:该规则提取数据后保存的字段名。
- datatype:该规则提取数据的结果类型,一个字符串或者一个列表。目前支持str和list。
- regex:通过xpath匹配到字段以后,使用regex进行二次匹配,匹配出精确数据。默认值为null。
- format:配合regex使用。当regex二次匹配以后,使用format重新格式化匹配的结果。默认值为null。
注意:fields支持提取制定xpath路径内包含HTML标签的正文,样例如下:
{
"type": "xpath",
"value": "//div[@class=\"content\"]",
"field": "news_content_html",
"datatype": "html",
"gzip": true
}
XPATH编写合集
使用xpath定位可以通过HTML节点的属性,例如id或者class定位。
通过class定位
//div[@class=\"fl txt title_02\"]/a
定位class为“fl txt title_02”的div标签。
通过class和id定位
//div[@class="main_content"]/div[@id="zoom"]
定位class为“main_content”的div标签下,id为“zoom”的div标签。
使用contains定位
然而有时使用绝对相等的方式无法匹配所有的标签,我们可以使用关键字contains。例如:
//div[contains(@class, 'listn-right')]//div[contains(@class, 'listn-con')]//a
定位class中包含“listn-right”的所有div标签下面,class中包含“listn-con”的所有div标签下的所有a标签
表格定位
表格定位非常复杂,最普通的定位方式就是按照单元格行列定位。例如:
/table//tr[2]/td[1]/text()
我们也可以结合表格内容进行相对定位,通过使用XPath Axes定位单元格。例如:
//td[contains(text(), '约定开工时间')]/following-sibling::td[1]/text()
上例中通过“约定开工时间”单元格定位该单元格旁边的单元格内容。不过这种方法只适合同一行相邻列的情况。如图所示:
![]()
表格定位:示例2
有时一个表格中有几个单元格有相似的文字,此时使用contains可能会定位到错误的单元格。如图所示:

如果我们要定位“年报”的单元格,如果使用以下xpath表达式可能会导致匹配到错误的列:
//tr/td[contains(text(), '年报')]
在这种情况下,我们可以使用以下方案:
//tr/td[text()='年报:']
表格定位:示例3
在这种情况中,单元格中的文字被其他HTML标签包围,这种情况下使用text()拿不到任何内容。例如上例中的“投资者查询账号开立率”这个单元格。HTML源代码如图所示:

如需要通过定位单元格中div标签内容,需要使用如下xpath表达式:
//tr/td[contains(./div, '投资者查询账号开立率')]
条件定位
例如以下样例我们只需要定位有时间的项,那么我们需要在xpath中判断是否有时间内容:

该样例的HTML源代码实现方式如下:

此时,我们的xpath表达式可以这样写:
//ul[contains(@class, 'gu-iconList')]/li[contains(./span, '2')]//a
这样我们就能只筛选li的子标签span包含数字2的所有li标签。
提取当前标签和子标签的内容
当需要提取标签中的内容和子标签中的内容时,可能会存在获取不到自标签的内容,如图:
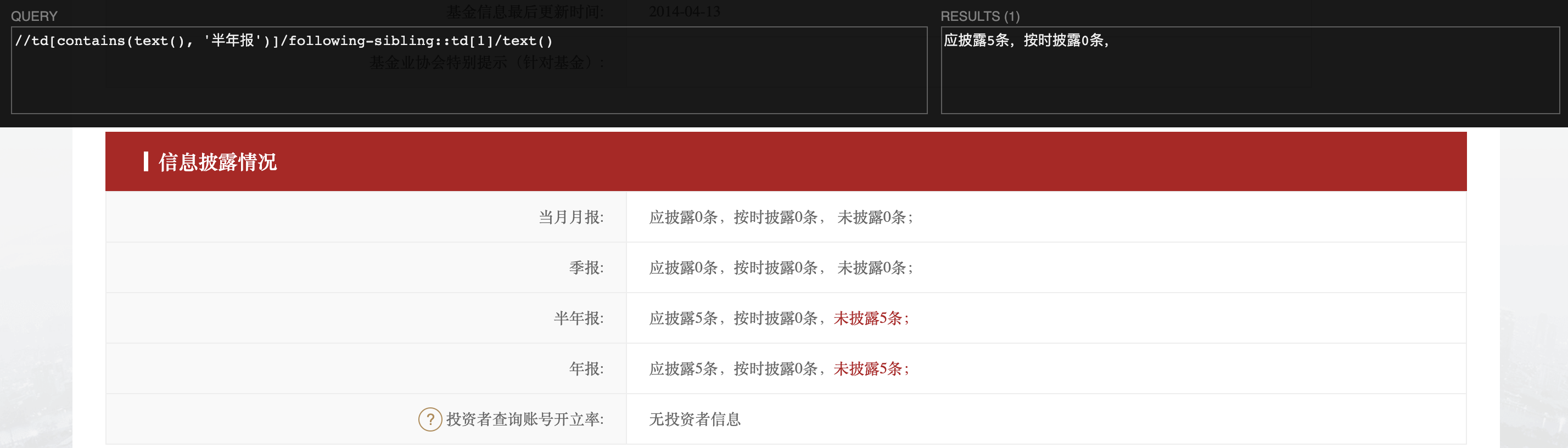
此时可以使用递归方式获取:
//td[contains(text(), '半年报')]/following-sibling::td[1]//text()
排除特定子标签
当我们要排除id为wenzhang-content的div下面的title,style,meta标签,如图:

此时,我们可以把xpath写为:
//div[@id='wenzhang-content']/*[not(name()="title" or name()="style" or name()="meta" )]
排除具有特定style的子标签
当我们要排除id为wenzhang-content的div下面所有居中的p标签,如图中第一个和第二个p标签:

此时,我们可以把xpath写为:
//div[@id='wenzhang-content']/p[not(contains(@style, "center"))]
xpath选择范围
当我们想要选择子标签列表中某个范围内的子标签,如图,我们只想选取第三个开始的所有子标签:
此时,我们可以把xpath写为:
#第二个后面的标签 //div[@id='wenzhang-content']/p[position()>2] #选择第三个,第四个标签 //div[@id='wenzhang-content']/p[position()>2 and position()<5] #选择最后一个标签 //div[@id='wenzhang-content']/p[last()] #选择倒数第二个 //div[@id='wenzhang-content']/p[last()-2]
更多xpath相关函数,可以参考:
https://developer.mozilla.org/en-US/docs/Web/XPath/Functions