消息队列目前是实现系统异步处理的成熟中间件。消息由生产者创建并推送至消息队列,由消息队列缓存,最后由消费者消费。Kafka作为消息队列中间件中应用非常广泛的一款产品,能够有效地分离生产者和消费者之间紧耦合的关系,并且实现了生产者和消费者独立伸缩的能力。因此,搭建一套高可用的Kafka集群将是系统中非常重要的一个环节。
Kafka参数
Kafka的节点角色叫做broker。假设我们将使用3台服务器搭建一个Kafka集群,那么这个集群中有3个broker。Kafka中的消息队列由topic区分。在Kafka的配置文件中还有一个partitions的概念。假设我们设置partitions为12,那么我们可以理解为将一个队列切分成12份。如果在一个具有3个broker节点的集群中,12个partitions将平均分散在3个节点上。以下是一个partitions为3的消息分布情况(此时replication副本设置为1,将在下一节讨论):
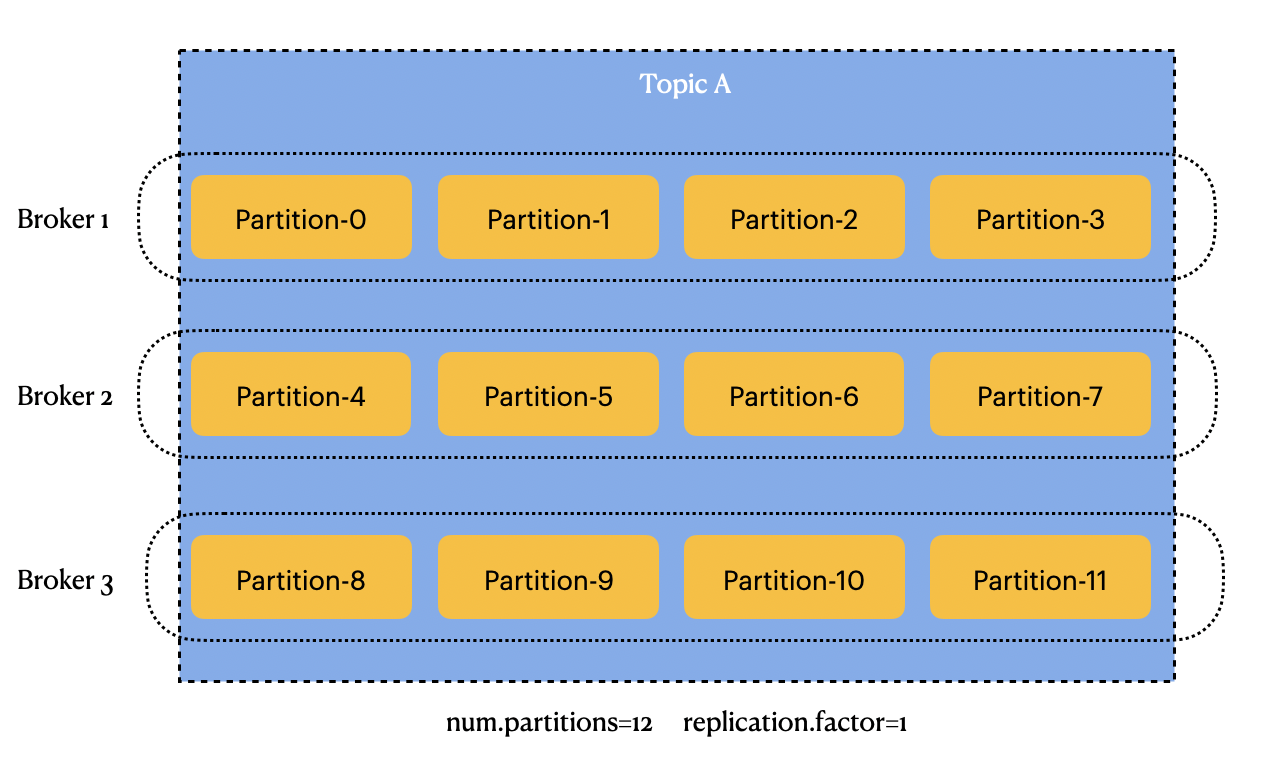
要完成Kafka的高可用还需要设置replication这个参数。如果replication设置为3,那么每一个partition有3个副本。此时partition的分布情况如下:

如果所示,broker的数据量和partitions最好是倍数关系,这样能够使得kafka每一个节点的负载相对均衡。replication数小于等于broker数量就可以,这样能够保证高可用。
Kafka集群搭建
这里就不详细介绍Kafka的集群搭建过程了。有兴趣的朋友可以参考这篇文章《High Performance and Availability Kafka Cluster》
Kafka集群扩容方案
当Kafka集群需要扩容的时候,例如增加一台新的broker,是需要手动执行脚本重新均衡topic的所有partitions的。本文将不展开讨论,有兴趣的朋友可以参考本文《Automatically migrating data to new machines》
ConsumerGroup概念
当消费者连接到Kafka消费数据时,需要定义一个ConsumerGroup。处于同一个分组的消费者订阅同一个topic时,访问不同的partitions获取消息。例如上图中我配置了12个partitions。如果同一个分组中有2个消费者,默认情况下该两个消费者分别访问partitions0-5和partitions6-11的消息。如果同一个分组中有3个消费者,那么这3个消费者分别访问partitions0-3,partitions4-7,partitions8-11的消息。消费者的数量大于分区数时,会导致多余的消费者获取不到数据。
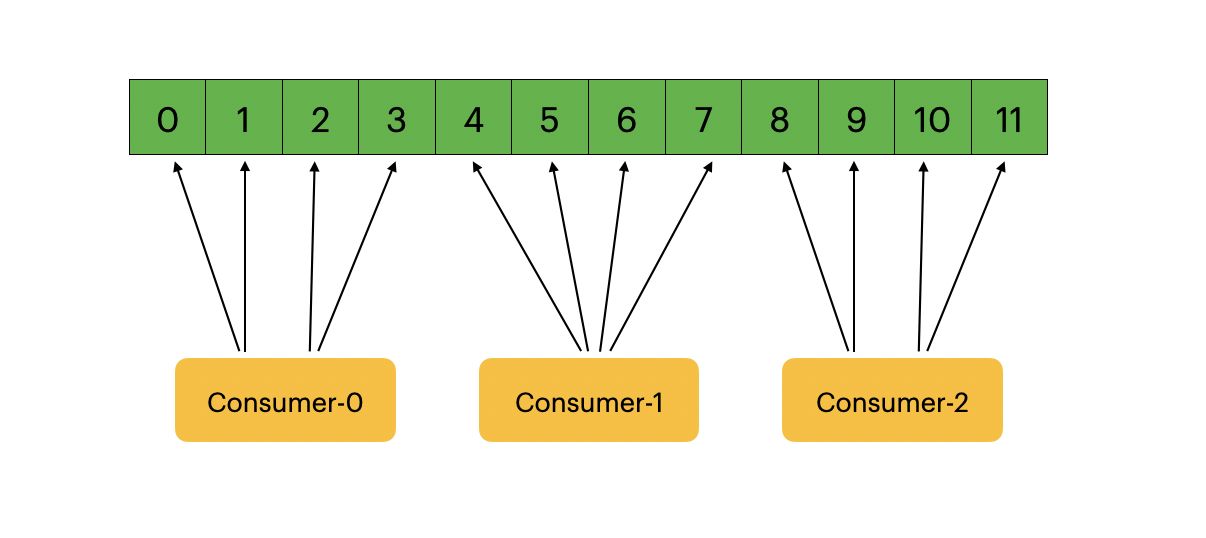
如果有2个消费者需要订阅同一个topic并且需要对该topic中的数据做不同的处理,那么这2个消费者必须分配到不同的ConsumerGroup中。
参考文档
kafka消费者再平衡机制