上篇文章《上市公司公告和基金公告PDF数据解析》中提到使用pdfplumber解析基金公告中的表格。然而由于各种各样的原因,在开发的过程中需要微调代码,从而提高PDF中表格的识别精确度。因此如果能够通过可视化的方式,即所见即所得的方式,进行表格提取单步调试,可以事半功倍地提升工作效率。
目前比较流行的数据可视化方案是Pandas加Jupyter的单步调试方案。使用Pandas的DataFrame可以非常方便的创建表格数据,并且利用Pandas的Style和Jupyter Notebook实现可视化调试。除此之外,pdfplumber也提供了自己的数据可视化调试方案。
使用数据可视化调试PDF不规则表格识别提取
之前我们描述过在PDF中如果表格缺少横线或者竖线,就会导致整行或者整列的缺失。pdfplumber在解析表格过程中默认使用line作为表格的水平边框和垂直边框策略。如果缺失横线或者竖线的话,对应的行列就不在表格内。因此要解决这个问题,就需要调整默认的table_settings参数。以下将以数据可视化的方式调试table_settings参数,使表格识别准确度达到一个比较合理的水平。
调整垂直策略提高缺失竖线表格识别准确度
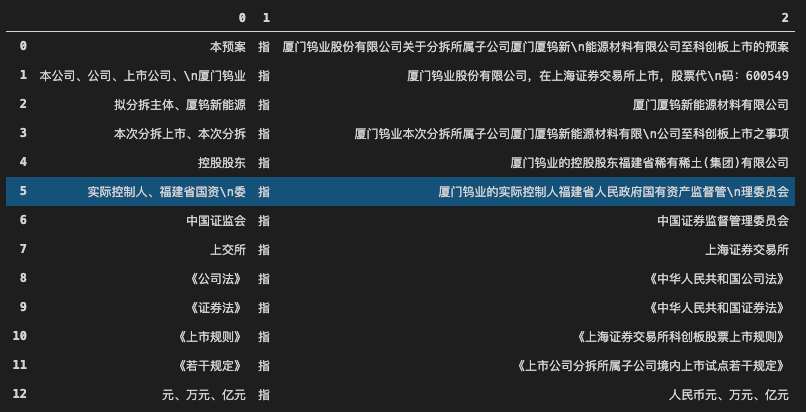
首先我们来看看使用table_settings默认参数识别《关于分拆所属子公司厦门厦钨新能源材料有限公司至科创板上市的预案》中第3页的表格。如图所示:

以下是table_settings默认参数列表:
tableSettings = {
"vertical_strategy": "lines",
"horizontal_strategy": "lines",
"explicit_vertical_lines": [],
"explicit_horizontal_lines": [],
"snap_tolerance": 3,
"join_tolerance": 3,
"edge_min_length": 3,
"min_words_vertical": 3,
"min_words_horizontal": 1,
"keep_blank_chars": False,
"text_tolerance": 3,
"text_x_tolerance": None,
"text_y_tolerance": None,
"intersection_tolerance": 3,
"intersection_x_tolerance": None,
"intersection_y_tolerance": None,
}
如果将vertical_strategy设置为“text”:
tableSettings["vertical_strategy"] = "text"
可以得到以下效果:
附上源代码:
import pdfplumber
import pandas as pd
tableSettings = {
"vertical_strategy": "lines",
"horizontal_strategy": "lines",
"explicit_vertical_lines": [],
"explicit_horizontal_lines": [],
"snap_tolerance": 3,
"join_tolerance": 3,
"edge_min_length": 3,
"min_words_vertical": 3,
"min_words_horizontal": 1,
"keep_blank_chars": False,
"text_tolerance": 3,
"text_x_tolerance": None,
"text_y_tolerance": None,
"intersection_tolerance": 3,
"intersection_x_tolerance": None,
"intersection_y_tolerance": None,
}
pdf = pdfplumber.open("sample/1.pdf")
page1 = pdf.pages[2]
tableSettings["vertical_strategy"] = "text"
table = page1.extract_table(tableSettings)
df = pd.DataFrame(table)
除了使用text作为垂直策略,我们还可以使用explicit和explicit_vertical_lines组合实现。这种方式类似于在explicit_vertical_lines中定义若干根竖线或者竖线的横坐标点。这个会复杂很多,相当于自定义边框线,不在本文讨论范围之内。
调整水平策略提高缺失横线表格识别准确度
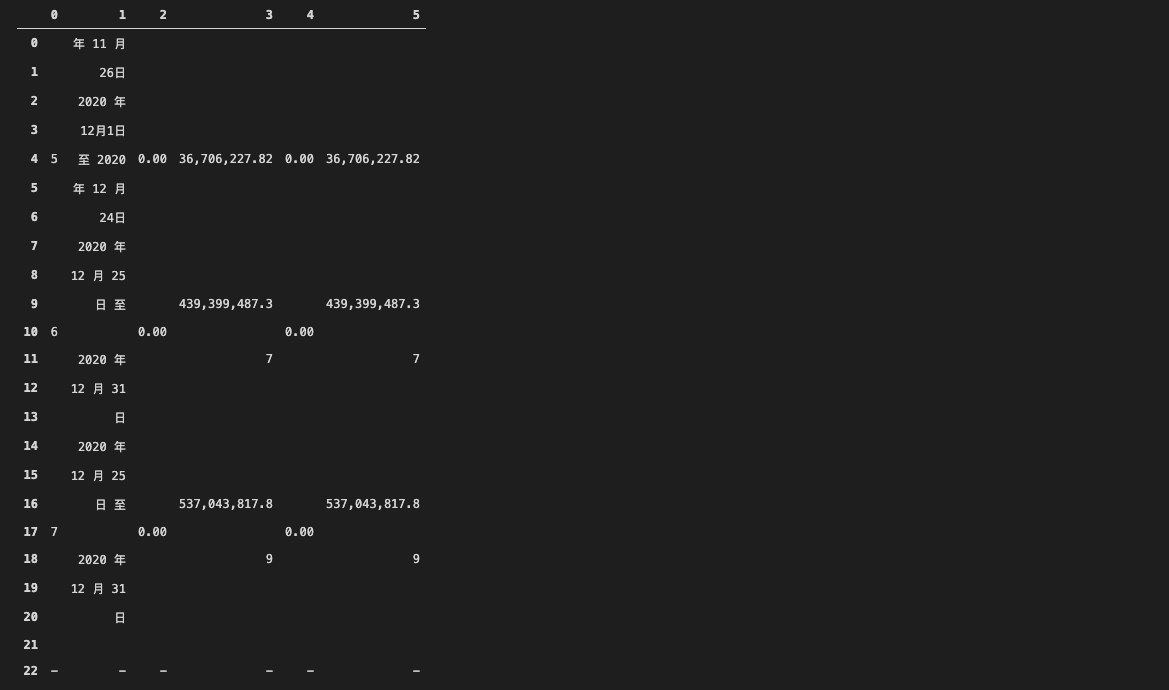
使用同样的方法,我们也可以处理PDF文档中缺失横线的表格。只需要将horizontal_strategy设置为text即可。但是由于min_words_horizontal的情况,会导致一个单元格中多行文字会被识别为单独的行。因此缺失横线表格在默认情况下会识别如图所示:

但是将horizontal_strategy设置为text以后,就会发生多行和缺行的问题:
更多需要思考的问题
pdfplumber提供了多种方式来识别表格边框。但是对于复杂的表格,尤其在横线缺失的情况,使用text策略的表现并不是很好。因此,最好的方案是使用explicit和explicit_horizontal_lines的方式,但是如何初始化explicit_horizontal_lines数组就是另外一个问题。explicit_horizontal_lines支持坐标或者line、rect、curve对象。如果能够找一种方法可以精确的定位坐标,就可以精确的自定义边框。从而更好的实现表格识别。