在开发数据爬虫过程中,xpath和正则表达式是两个最常用的数据提取工具。对于xml或html等结构化非常强的数据结构,xpath因为其高性能更是独一无二的首选。 对于完全不了解xpath的朋友可以看看w3school的xpath基础教程。而正则表达式的使用场景就更加广泛了,对于xpath无法提取的数据,正则表达式可以轻而易举地实现。当然,正则表达式唯一的缺点就是性能比较低,对于大篇幅的文本在做数据提取是会消耗比较长的时间。正则表达式没有官方的基础教程,由于大多数的爬虫使用python开发,这里就给出一个python的正则表达式文档。
xpath工具
两眼一抹黑手写xpath效率是很低的,如果xpath用来提取html页面的数据,我们可以使用chrome浏览器的“XPath Helper”插件和chrome的开发者模式辅助完成(官方chrome开发者工具文档)。这个插件可以所见即所得地帮助我们实现xpath的编写。例如,需要提取本文中的标题,可以使用这种方法定位xpath。
//h1[@class="entry-title"]
首先,我们可以在chrome开发者模式中找到标题对应的HTML标签,然后使用xpath的语法定位到标签内容。随后,我们在Xpath Helper中输入以上表达式以后,如果xpath正确,就会在原有页面中高亮出来。如图所示:
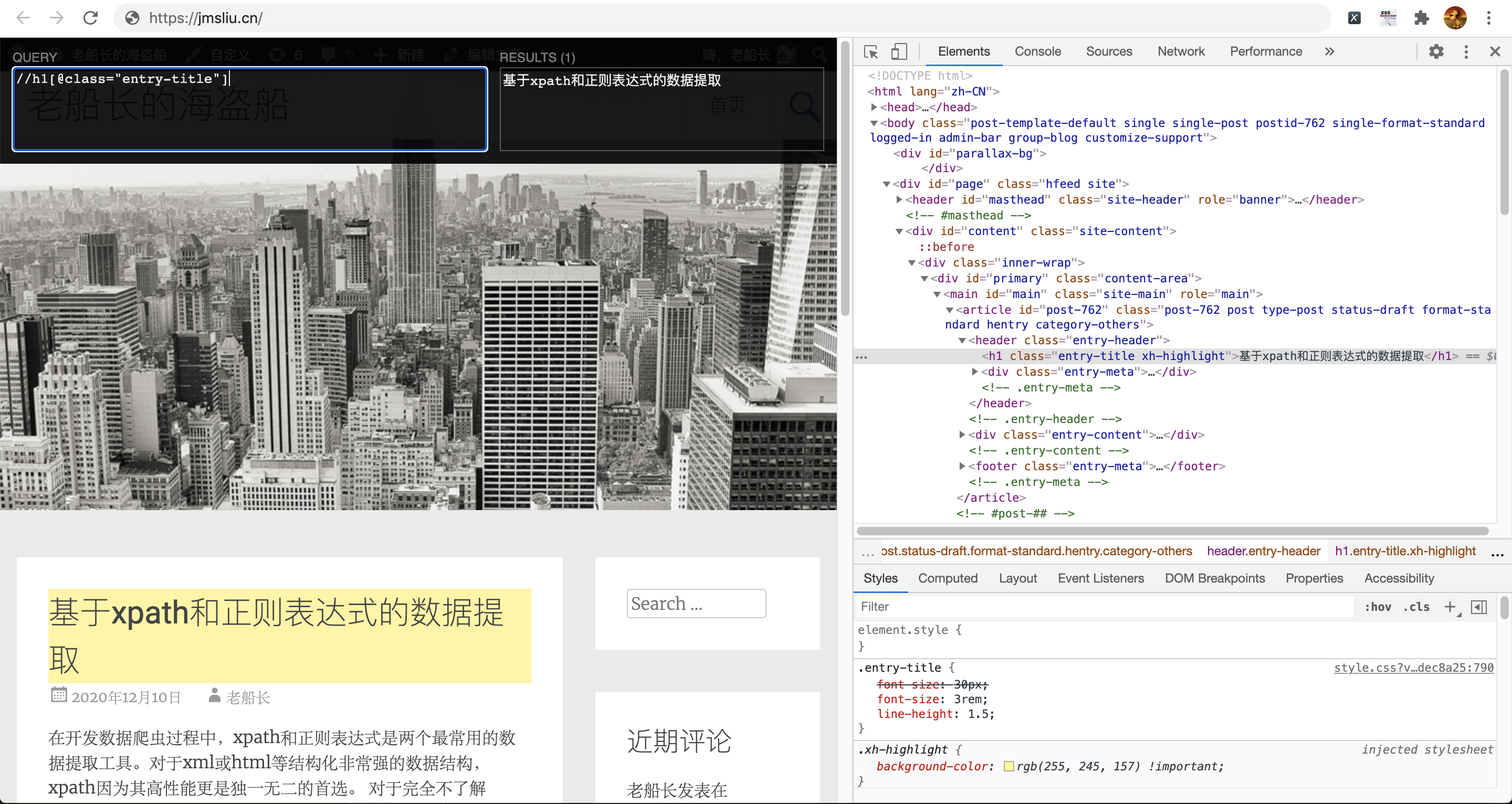
当然xpath是非常灵活的,需要提取数据的写法有很多种。例如,以上提取标题的表达式,也可以写成以下两种形式,只要能定位到页面元素,选择最优雅的写法即可。
//h1[contains(@class, "entry-title")]
或者
//title
regex正则表达式工具
目前并没有好用的类似于xpath helper的正则表达式插件。最好的办法就是把网页源代码手动拷贝到notepad++或者vs code等编辑器里面,然后使用这些编辑器中的正则表达式查询功能验证正则表达式的正确性。同样使用提取标题这个示例,在vs code中可以这样验证:
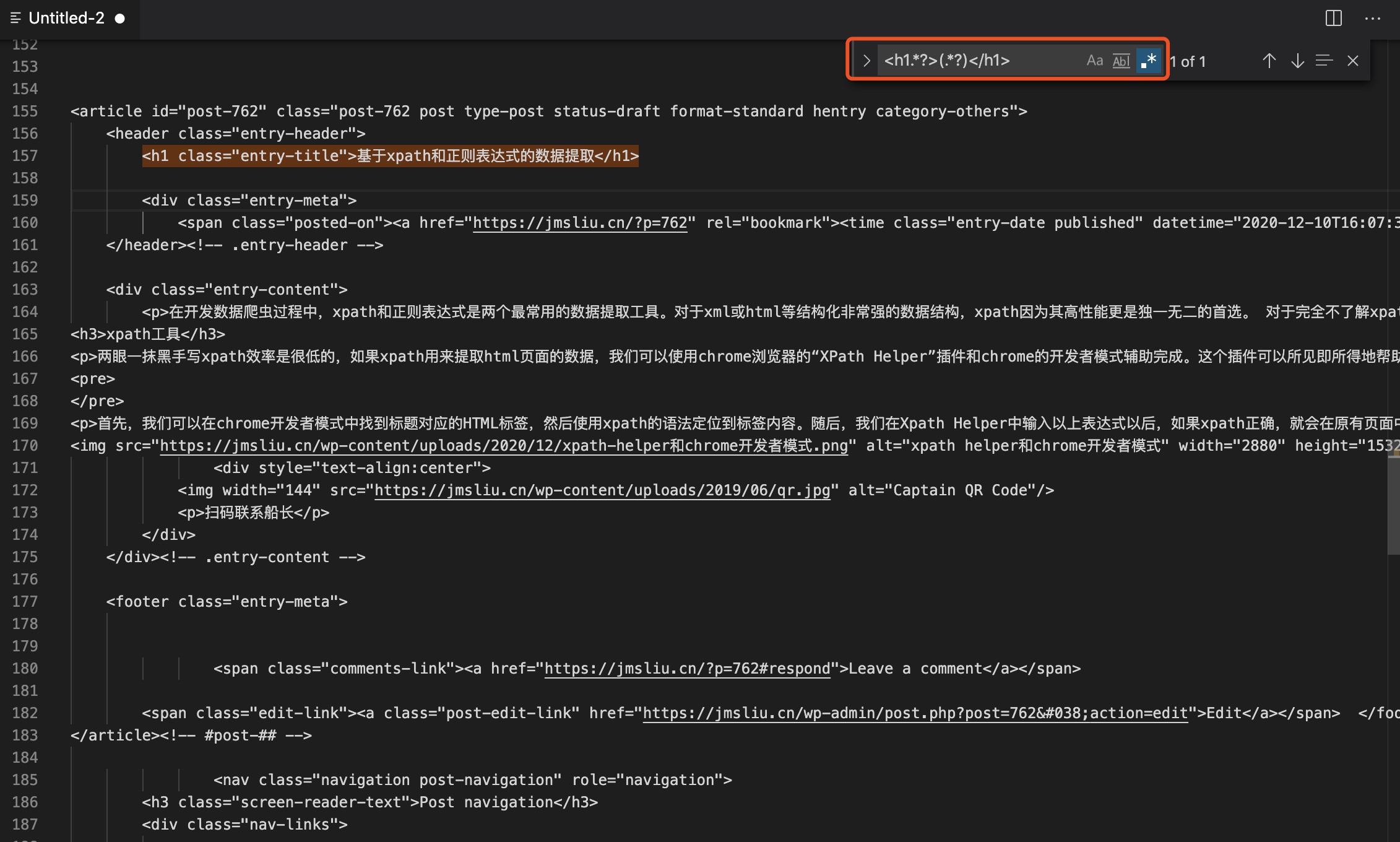
如图所示,如果使用正则表达式的方式提取标题的话,需要使用以下表达式:
<h1.*?>(.*?)</h1>
相比之下,要比xpath难以理解很多,并且在性能上也相对比较低。因此如果能够使用xpath提取数据,最好使用xpath。在不能使用xpath提取数据的情况下,我们可以选择功能更加强大,但是性能相对较低的正则表达式。