相对于Scrapy框架,增加了Kafka和Redis模块的Scrapy Cluster要复杂的多。因此要搞清楚各大模块之间是如何工作的,就至关重要了。在Scrapy Cluster框架中,有三大系统模块:Kafka,Redis,Scrapy Spider。其中Kafka和Redis之间的消息传递是通过kafka_monitor.py组建实现的(单向连接)。Scrapy Spider和Redis的连接是通过distributed_scheduler.py实现的(双向连接)。Scrapy Spider与Kafka之间的连接是通过pipelines.py里面的KafkaPipeline类实现的(单向连接)。
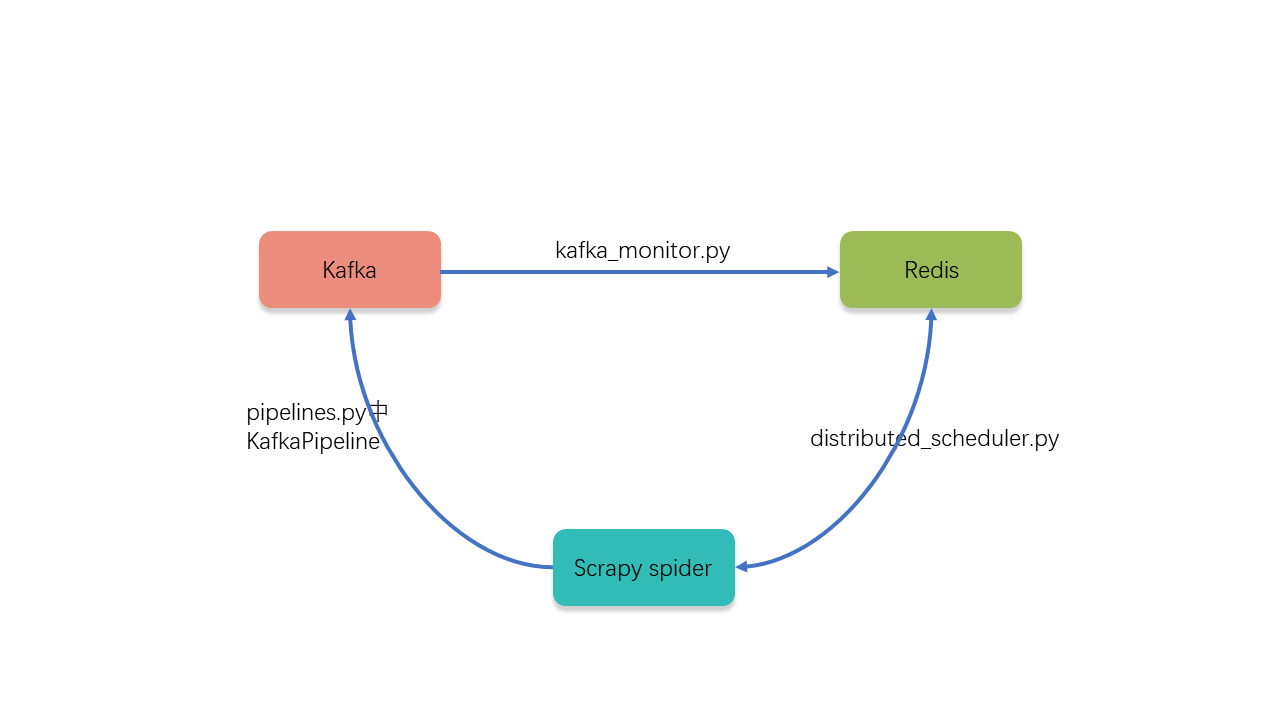
我们可以把由Kafka,Redis和Scrapy Spider组成的系统看作一个封闭系统,所有数据输入和输出,都是通过Kafka实现的。我们可以通过向Kafka中特定的Topic发送消息使整个系统运转起来,也可以通过向Kafka发送消息,获取系统内部的状态(虽然可以把外部系统连接到Redis服务器,但是不建议这么做,主要是会提高系统的复杂性)。为了能够梳理清楚整个系统的消息流,本文将先讲解以下Kafka和Redis之间的消息生产和消费。
如上图描述,Kafka和Redis之间是通过kafka_monitor.py文件来实现消息的消费和传递的。kafka_monitor.py是一个常驻内存的程序,每隔一段时间就会连接kafka去消费数据。以下是其中一段代码(开源项目,可以访问Github代码库):
def _main_loop(self):
'''
Continuous loop that reads from a kafka topic and tries to validate
incoming messages
'''
self.logger.debug("Processing messages")
old_time = 0
while True:
self._process_messages()
if self.settings['STATS_DUMP'] != 0:
new_time = int(old_div(time.time(), self.settings['STATS_DUMP']))
# only log every X seconds
if new_time != old_time:
self._dump_stats()
old_time = new_time
self._report_self()
time.sleep(self.settings['SLEEP_TIME'])
其中SLEEP_TIME是可以在localsettings文件里面设置的。因此,kafka_monitor.py启动以后,可以理解为一直在监听kafka是否有新消息。另外,这里需要注意的是,在Scrapy Cluster里面,默认情况下,所有的爬取消息和状态查询消息,生产者都会推送到名为demo.incoming的Topic中。所以,kafka_monitor.py也会默认监听此Topic。下面我们就手动向Kafka推送两条消息。
为了方便测试,kafka_monitor.py也提供了向kafka推送消息的功能。我个人认为,该功能就是为了大家手动测试用的。下面我们首先推送一条爬取消息。只需要在命令行中键入:
python kafka_monitor.py feed '{"url": "http://jmsliu.cn/","appid": "myapp","crawlid": "jmstest","spiderid": "link"}'
如果推送成功,会在命令行终端输出以下内容:
2019-06-13 20:56:44,190 [kafka-monitor] INFO: Feeding JSON into demo.incoming
{
"url": "http://jmsliu.cn/",
"spiderid": "link",
"crawlid": "jmstest",
"appid": "myapp"
}
2019-06-13 20:56:44,331 [kafka-monitor] INFO: Successfully fed item to Kafka
Scrapy Cluster中爬取消息的生产与消费
随后,kafka_monitor.py作为消费者会从名为demo.incoming的Topic中把消息消费掉,并且在方法_process_messages调用相应的plugin处理相关消息。例如,以上示例中的爬取消息,会调用plugins/scraper_handler.py中的ScraperHandler类来处理。有兴趣的朋友可以看一下该文件的源代码,主要是handle方法。总的来说,kafka_monitor.py作为消费者会做以下工作:
- 循环从kafka中消费消息,参考
_main_loop函数 - 调用所有的plugin处理消息,参考
_process_messages函数 plugins/scraper_handler.py中的ScraperHandler类处理爬取消息- 把爬取消息转化为爬取对象,并发送到Redis中,键值为link:jmsliu.cn:queue,参考
handle函数
以上爬取消息被转化为对象后会发送到Redis,保存在link:jmsliu.cn:queue键值中。类型为zset(排序集合)。以下为爬取对象在zset中的值:
{"allowed_domains":null,"allow_regex":null,"crawlid":"jmstest","url":"http:\/\/jmsliu.cn\/","expires":0,"ts":1560412604.2721540928,"priority":1,"deny_regex":null,"spiderid":"link","attrs":null,"appid":"myapp","cookie":null,"useragent":null,"deny_extensions":null,"maxdepth":0}
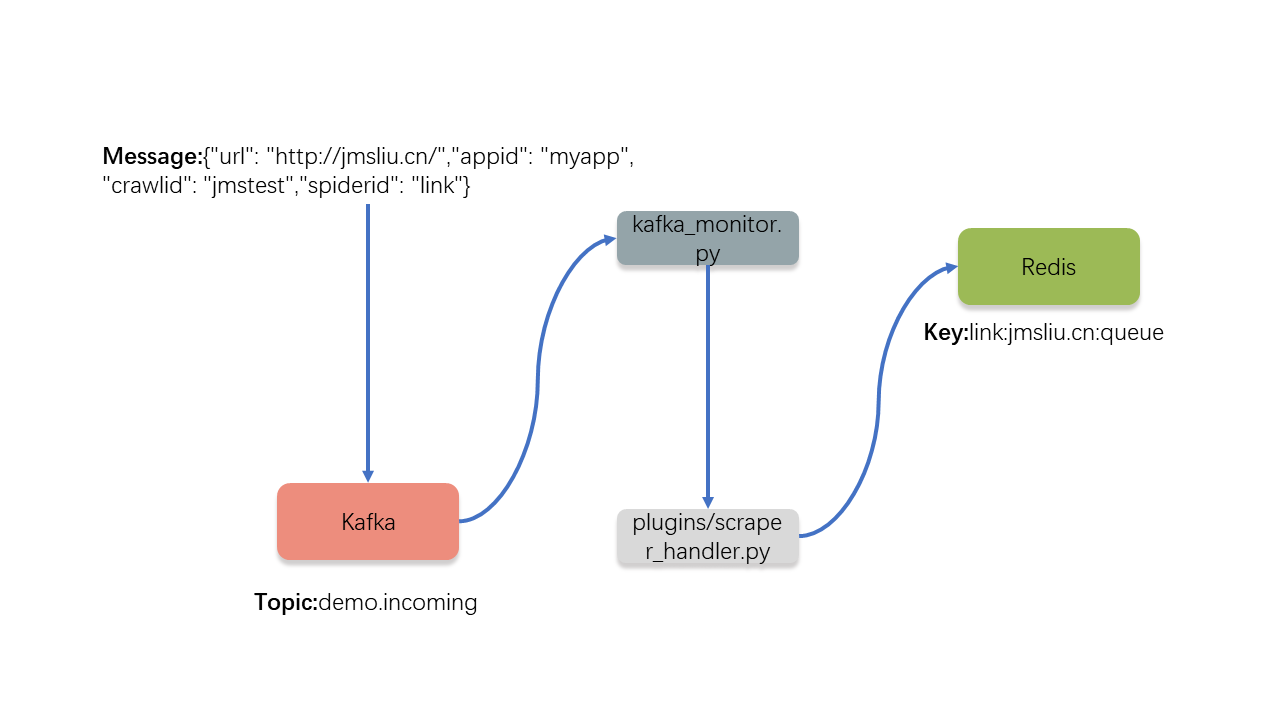
如果在Scrapy Cluster系统中启动了名为link的爬虫,该爬取对象就会被取出。这部分内容已经超出了本文的范围,将在后续的文章中详细讲解。
Scrapy Cluster中状态查询消息的生产与消费
本节我们将演示如何使用kafka_monitor.py作为生产者推送一条状态查询指令到Kafka中,然后再作为消费者把消息取出来,并发送给Redis。同样我们只需在命令行中键入:
python kafka_monitor.py feed '{"action":"info","appid":"myapp","uuid":"1234567890","crawlid":"jmstest","spiderid":"link"}'
如果推送成功,会在命令行终端输出以下内容:
2019-06-13 21:19:51,436 [kafka-monitor] INFO: Feeding JSON into demo.incoming
{
"action": "info",
"crawlid": "jmstest",
"spiderid": "link",
"uuid": "1234567890",
"appid": "myapp"
}
2019-06-13 21:19:51,497 [kafka-monitor] INFO: Successfully fed item to Kafka
与爬取消息类似,kafka_monitor.py会消费该消息,并发送到所有的plugin里面去处理。与爬取消息不同的是,状态查询消息会被plugins/action_handler.py处理。总的来说,kafka_monitor.py作为消费者会做以下工作:
- 循环从kafka中消费消息,参考
_main_loop函数 - 调用所有的plugin处理消息,参考
_process_messages函数 plugins/action_handler.py中的ActionHandler类处理爬取消息- 把爬取消息转化为爬取对象,并发送到Redis中,键值为info:link:myapp:jmstest,参考
handle函数
以上爬取消息被转化为对象后会发送到Redis,保存在info:link:myapp:jmstest键值中。类型为string(字符串),值为1234567890(即uuid)。如果在Scrapy Cluster系统中启动了redis_monitor.py,该查询对象就会被取出。这部分内容已经超出了本文的范围,将在后续的文章中详细讲解。

注意:以上代码中我们使用kafka_monitor.py作为生产者向Kafka推送数据。这个完全是为了做系统调试。在真正的产品生产环境中,kafka_monitor.py所扮演的最重要的角色为消息的消费者,并通过不同的plugin来处理消息。所有的plugin都在plugins发文件夹中可以找到。
扩展阅读
上节中,我们已经演示了使用kafka_monitor.py手动推送消息,最后这些消息通过kafka_monitor.py消费并转化为对象存放到Redis,并等待下一步的处理。下面我们尝试在终端中打开一个监听kafka的名为demo.outbound_firehose的Topic,然后在另外一个窗口运行redis_monitor.py会发生什么?空谈误国,实干兴邦。下面我们通过向Kafka发送消息并观察输出来体会Scrapy Cluster中的消息生产和消费。
查看Info指令的输出结果
我们在终端窗口A中运行以下指令(注意文件夹路径,在kafka-monitor路径下执行):
python kafkadump.py dump -t demo.outbound_firehose
在另外一个终端窗口B中运行以下指令(注意文件夹路径,在redis-monitor路径下执行):
python redis_monitor.py
在第三个终端窗口C中运行以下指令(注意文件夹路径,在kafka-monitor路径下执行):
python kafka_monitor.py feed '{"action":"info","appid":"myapp","uuid":"1234567890","crawlid":"jmstest","spiderid":"link"}'
随后,在终端窗口A中会出现以下内容:
{u'server_time': 1560415131, u'crawlid': u'jmstest', u'total_pending': 1, u'total_domains': 1, u'spiderid': u'link', u'appid': u'myapp', u'domains': {u'jmsliu.cn': {u'low_priority': 1, u'high_priority': 1, u'total': 1}}, u'uuid': u'1234567890'}
我们再次在第三个终端窗口C中运行以下指令(注意文件夹路径,在kafka-monitor路径下执行):
python kafka_monitor.py feed '{"url": "http://jmsliu.cn/","appid": "myapp","crawlid": "jmstest","spiderid": "link"}'
我们再次在第三个终端窗口C中运行以下指令(注意文件夹路径,在kafka-monitor路径下执行):
python kafka_monitor.py feed '{"action":"info","appid":"myapp","uuid":"1234567890","crawlid":"jmstest","spiderid":"link"}'
这时,在终端窗口A中会出现以下内容:
{u'server_time': 1560415399, u'crawlid': u'jmstest', u'total_pending': 2, u'total_domains': 1, u'spiderid': u'link', u'appid': u'myapp', u'domains': {u'jmsliu.cn': {u'low_priority': 1, u'high_priority': 1, u'total': 2}}, u'uuid': u'1234567890'}
大家想一想,整个系统发生了什么?