本文是《M3U8流视频数据爬虫详解》系列教程中的第三篇。前两篇《M3U8视频文件详解》和《M3U8视频网络数据分析与爬虫设计》分别介绍了M3U8文件的基础知识。并且通过详细案例,介绍和讲解了使用Chrome开发者工具分析页面数据,并从数据记录中找到了最关键的数据文件和访问方法。最后,根据页面分析结果,我们给出了一套具体的M3U8视频爬虫设计思路。在本文中,我们将在上一篇的基础上,以实际案例,根据爬虫设计思路,实现一套具体的M3U8视频爬虫程序。
免责申明:本文是以教育为目的的教学讲解,不涉及和教唆任何非法获取数据,非法使用数据,和非法占有数据的行为。对于没有经过授权的数据爬取行为都是违规的,违法的。对于任何个人,团体或者机构,运用该技术从事任何违法违规行为的,自担风险。
下载一级M3U8文件
本文使用的具体案例是阿里大学的教学视频网站,视频样例为:
https://edu.aliyun.com/lesson_137_1545#_1545
按照《M3U8视频网络数据分析与爬虫设计》文中的设计思路,首先我们要登陆该网页才能获取一级M3U8文件的下载地址。但是由于网站本身对于M3U8文件做了保护,页面中的M3U8文件URL只能访问一次。也就是说,如果浏览器访问了该页面,我们的爬虫程序就无法再次访问了。因此,我们需要在浏览器访问一级M3U8文件之前,获取该文件的URL地址,并阻止浏览器下载访问。这时我们又需要使用功能强大的Chrome开发者工具。
使用Chrome开发者工具从页面中获取URL数据
首先在Chrome浏览器中打开对应的网址(登陆以后的具体视频页面)。点击F12打开Chrome开发者工具。在“Sources”选项卡(顶端)中,点击“XHR/fetch Breakpoints”的加号,在编辑框中输入“m3u8”(本操作的意思是:当网页中有任何URL中包含m3u8字段的网络访问就暂停执行)。完成以上操作后重新刷新页面。此时Chrome开发者工具就会暂停在访问M3U8的代码位置。如图所示:
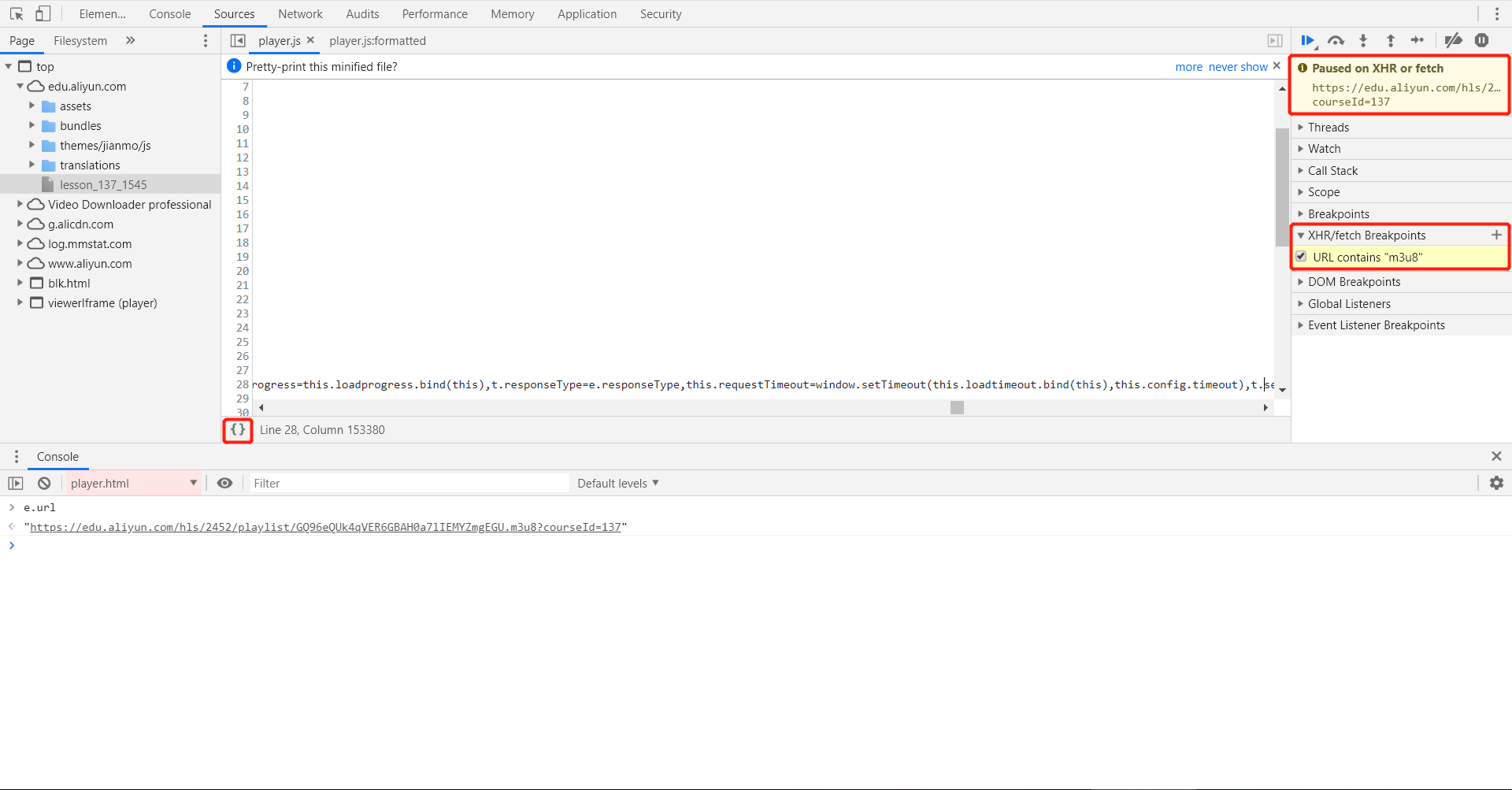
暂停后,我们可以点击左下方的{}图标提高暂停部分代码的可读性。随后Chrome开发者工具会显示一个相对容易阅读的源代码(Javascript源代码)。简单的分析以下JS代码,可以发现M3U8文件的URL藏在e.url变量中。我们可以在下方的“Console”窗口中输入e.url并回车,就能显示出来具体的URL地址。如图所示:
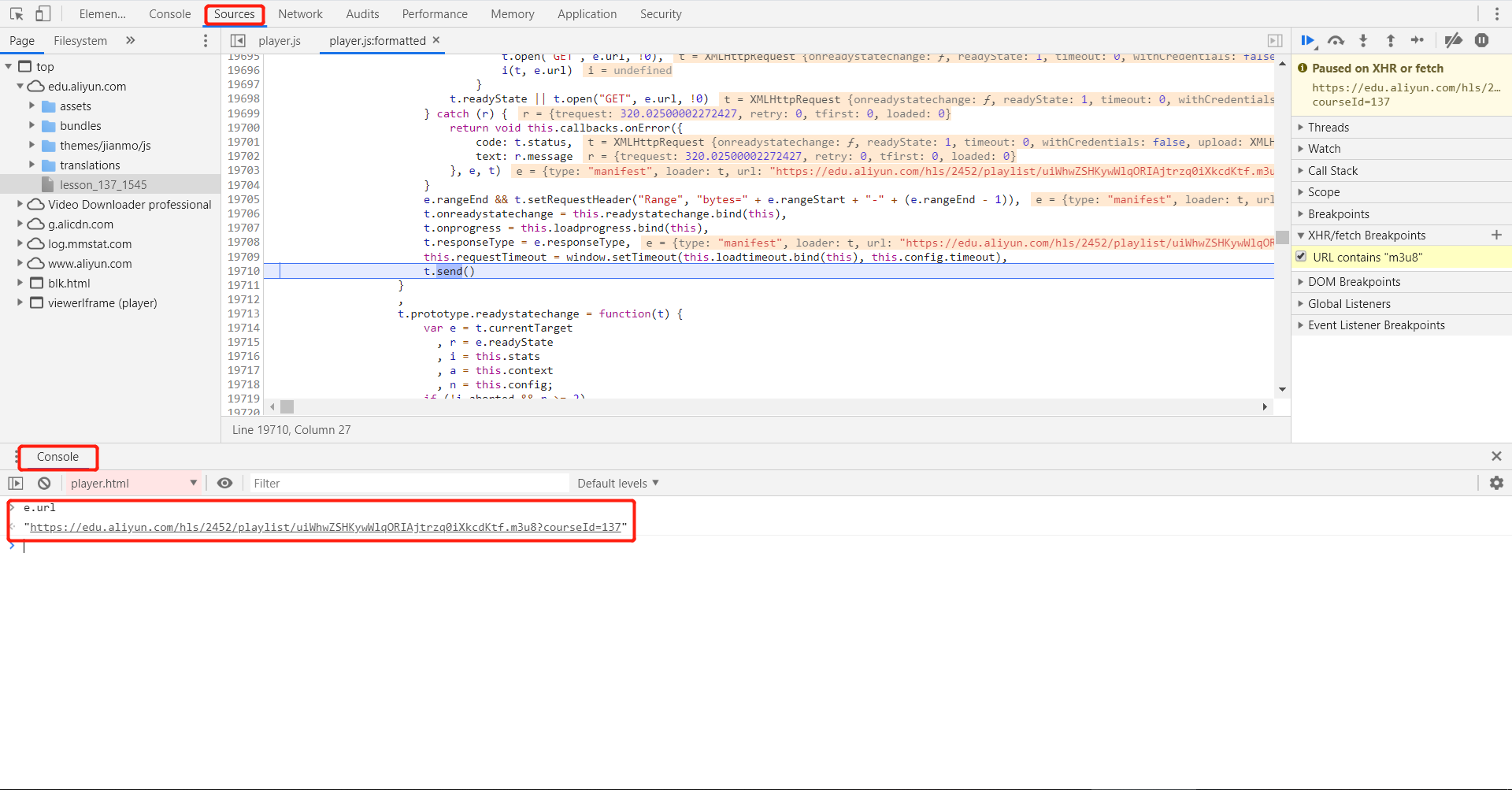
注意,由于阿里大学的视频URL每次访问都会发生变化,因此在实际操作中,具体的URL可能和本文中的不一样。
Python下载代码实现
获取到具体的URL以后,我们就可以开始编写爬虫下载程序了。本文将不讲解基础Python编程,对于没有任何Python编程背景的读者,建议自学以下Python基础编程,Python的Requests类等。以下是一段非常简单的HTTP下载代码,用来下载给定的URL(本文为M3U8文件和后面的TS文件,Key文件)。
# -*- coding: utf-8 -*-
import requests
url = "https://edu.aliyun.com/hls/2452/playlist/QhGsP7IelnAKHq4KPMPXxZWINSvyMYSD.m3u8?courseId=137"
try:
req = requests.get(url)
req.raise_for_status()
req.encoding = req.apparent_encoding
print(req.text)
except:
traceback.print_exc()
运行以上代码后,终端会显示以下内容(也就是M3U8的文件内容):
#EXTM3U #EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=704,NAME=标清 https://edu.aliyun.com/hls/2452/stream/sd/CyxsgtS0Rkr2uTZ2cv6dQCNbd4RVLj4E.m3u8?courseId=137 #EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=1096,NAME=高清 https://edu.aliyun.com/hls/2452/stream/hd/0FYIJA5K9E9Bq8ocFW3MJ3WSunGLBtul.m3u8?courseId=137
如果大家在运行代码过程中,代码返回404结果。大概率是因为该M3U8下载地址URL已经过期,需要重复以上步骤重新获取新的URL地址。至此,我们已经成功的下载了一级M3U8文件,并获得了两个不同网络环境下的二级M3U8文件URL。
下载二级M3U8文件
根据以上得出的结果,我们使用以下代码可以下载二级M3U8文件。
# -*- coding: utf-8 -*-
import requests
url = "https://edu.aliyun.com/hls/2452/stream/hd/0FYIJA5K9E9Bq8ocFW3MJ3WSunGLBtul.m3u8?courseId=137"
try:
req = requests.get(url)
req.raise_for_status()
req.encoding = req.apparent_encoding
print(req.text)
except Exception as e:
print(e)
运行代码以后,终端显示以下内容:
404 Client Error: Not Found for url: https://edu.aliyun.com/hls/2452/stream/hd/0FYIJA5K9E9Bq8ocFW3MJ3WSunGLBtul.m3u8?courseId=137
前文说过,阿里大学的视频URL只能访问一次,第二次访问就会出现404的错误。然后以上URL并没有被访问过。所以我们排除由于第二次访问而出现404的问题。因此推测很可能是需要验证登陆信息。所以,我们又要回到Chrome开发者工具中的网络窗口,点击一个网络数据记录并拷贝对应的Cookie,User-Agent和Referer等信息。如图所示:

随后将网络数据记录中的Cookie,User-Agent和Referer等信息拷贝到代码中(以上图片中的Cookie内容中有账号信息,因此进行了脱敏处理)。再重复以上步骤重新获取新的URL并运行代码。
# -*- coding: utf-8 -*-
import requests
url = "https://edu.aliyun.com/hls/2452/stream/sd/EyX0ufPyrPZecw5oyB8aQ5c4bDiQNVp6.m3u8?courseId=137"
try:
headers = {
"Cookie":"replace data with your own cookie from chrome developer tools",
"Referer":"https://edu.aliyun.com/bundles/customweb/lib/cloud-player/1.1.37.3/player.html",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
req = requests.get(url, headers=headers)
req.raise_for_status()
req.encoding = req.apparent_encoding
print(req.text)
except Exception as e:
print(e)
经过以上操作以后,终端会显示出完整的M3U8的文件内容,如图所示:

下载并保存密钥文件和IV数据
M3U8中的加密选项是可选的。因此不同的视频资源,有的会对TS文件加密并提供密钥(Key)文件URL地址和IV数据;有的则不会做任何处理;有些视频服务甚至对密钥(Key)文件进行了二次加密,类似于先要把密钥文件解密获取到密钥(Key)的元数据以后,再使用密钥(Key)的元数据对TS文件解密。比较庆幸的事,我们选择的样例视频,只使用原始的密钥和IV加密向量对TS文件进行加密。
阿里大学TS视频的密钥文件分析
在本例中,TS视频的加密方式也比较特殊。首先在M3U8文件中,每一个TS文件之前都有一个Key文件的URL和一个不一样的IV加密向量。但是在Chrome开发者工具中我们可以发现(如下图),其实页面上只加载了两个Key文件(第一个和第二个)。因此,我们可以推断第一个TS文件使用的是第一个key密钥进行解密的;第二个和以后的TS文件都是使用第二个Key密钥进行解密的。

另外,由于IV加密向量都是不一样的,那么从第二个和以后的TS文件用的是同一个IV加密向量么?这个问题需要验证。因为Key密钥文件和IV加密向量配对才能解密TS文件。我们使用Chrome开发者工具分析得出,在每一个TS文件被下载以后,都会调用一个onKeyLoading的方法。在该方法中,我们发现每一次TS文件对应得IV数据都是不一样的。例如下图中的IV数据,对应与M3U8中的第五条IV数据(42对应的16进制数为0x2a,174对应的16进制数为0xae)。

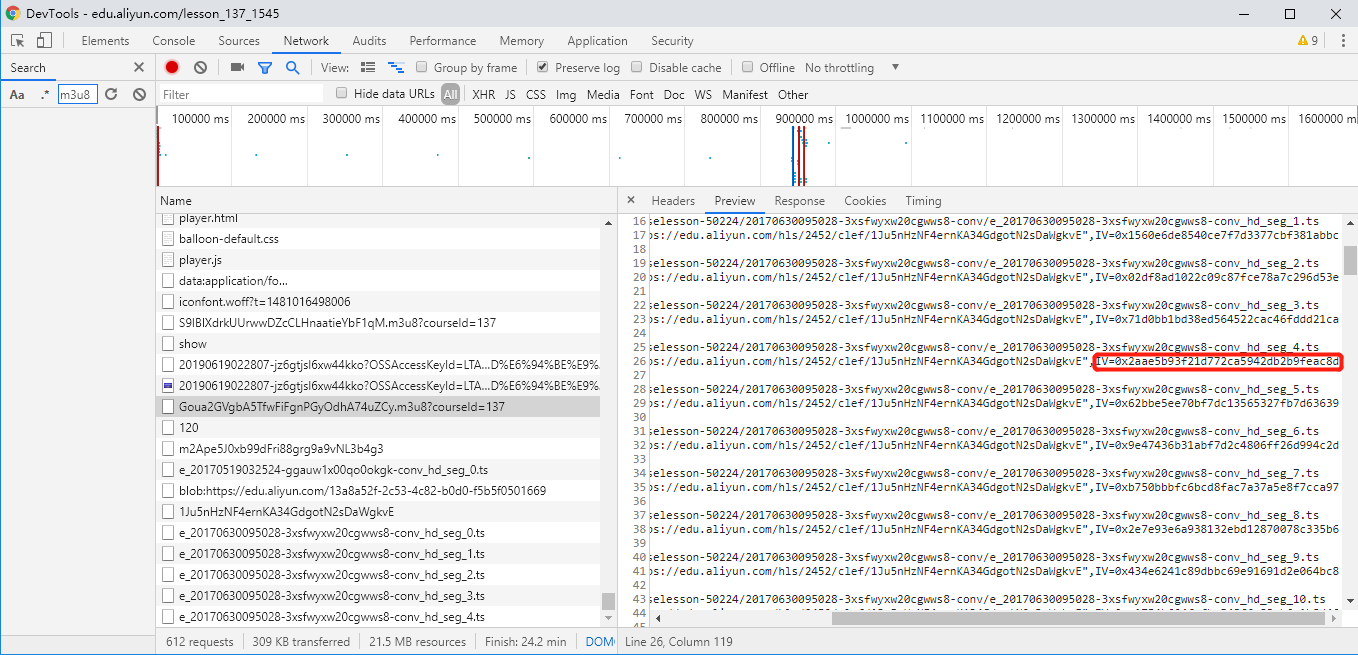
因此,我们只需要保存2个密钥文件,但是要保存所有的IV数据。以下是一个下载所有TS文件,Key文件,和IV文件的示例代码。注意,我们只下载前两个Key文件。
# -*- coding: utf-8 -*-
import requests
import os
import re
url = "https://edu.aliyun.com/hls/2452/stream/hd/xtCIX1dV4g6JEAwxcFpIdyS2CwKcNTJx.m3u8?courseId=137"
try:
headers = {
"Cookie":"replace data with your own cookie from chrome developer tools",
"Referer":"https://edu.aliyun.com/bundles/customweb/lib/cloud-player/1.1.37.3/player.html",
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
req = requests.get(url, headers=headers)
req.raise_for_status()
req.encoding = req.apparent_encoding
print(req.text)
content = req.text.split('\n')
currentKey = None
currentIV = None
keyNo = 0
for line in content:
if line[:10] == "#EXT-X-KEY":
if keyNo < 2:
keyNo = keyNo + 1
reg = r"URI=\"([^\"].*?)\""
result = re.findall(reg, line)
if len(result) > 0:
keyURL = result[0]
req = requests.get(keyURL, headers=headers)
req.raise_for_status()
currentKey = req.content
reg = r"IV=0x(.*)"
result = re.findall(reg, line)
if len(result) > 0:
currentIV = result[0]
elif len(line) > 0 and line[:1] != "#":
url = line
req = requests.get(url, headers=headers)
req.raise_for_status()
file_name = url.split('/')[-1].split('?')[0]
with open(os.path.join("./tmp", file_name), 'wb') as f:
f.write(req.content)
key_file_name = file_name + ".key"
with open(os.path.join("./tmp", key_file_name), 'wb') as f:
f.write(currentKey)
iv_file_name = file_name + ".iv"
vi = bytes.fromhex(currentIV)
with open(os.path.join("./tmp", iv_file_name), 'wb') as f:
f.write(vi)
elif line[:1] == "#EXT-X-ENDLIST":
break
else:
print("skip: " + line)
except Exception as e:
print(e)
如代码所示,TS文件,密钥文件(Key)和IV数据分别会存入以下文件:
- TS文件文件名为m3u8列表中的ts文件名,例如:e_20170630095028-3xsfwyxw20cgwws8-conv_hd_seg_0.ts
- Key文件名为ts文件名加后缀
.key,例如:e_20170630095028-3xsfwyxw20cgwws8-conv_hd_seg_0.ts.key;注意只有第一个和第二个Key的数据是下载下来的。后面的Key文件的数据和第二个Key完全相同 - IV文件名为ts文件名加后缀
.iv,例如:e_20170630095028-3xsfwyxw20cgwws8-conv_hd_seg_0.ts.iv
解密TS文件
不同的视频网址,提供的TS文件有可能被加密,也有可能没有加密。因此需要对具体的M3U8文件进行具体的分析。本文中的示例,每一个TS文件都被加密,而且使用的是不同的密钥和IV加密向量对。因此在上一节中,我们把TS文件,密钥文件(Key)和IV数据分别存在本地文件中。
阿里大学TS视频的密钥解密算法
一般AES加密算法使用的密钥是16个字节(128位)。但是我们发现阿里的Key密钥文件大小是20个字节(160位)。我们推测这个密钥文件是经过加密的,因此我们首先要解密这个密钥文件,获得真正的用来解密TS文件的密钥。。因此我们通过各种方式,最后找到了解密的方法。最终将20字节的密文解密为16字节的明文。由于这个解密过程和方法比较敏感,而且也不是本文的重点,因此就不贴出来了。有兴趣的朋友可以联系船长私下讨论。

使用AES-128解密TS文件
当我们获取了TS文件,密钥数据,和IV加密向量数据以后,我们就可以使用标准的AES算法解密TS文件了。以下是一段示例代码,分别从TS文件,密钥文件,和IV文件中把数据读出来,然后通过我们独有的阿里视频密钥解密程序把密文密钥转成明文密钥,随后调用AES解密TS数据,并把结果保存在result.ts文件中。
# -*- coding: utf-8 -*-
from keydecryptor.ali import AliKeyDecryptor
from Crypto.Cipher import AES
video = None
key = None
iv = None
file_name = "a.ts"
with open(os.path.join(".", file_name), 'rb') as f:
video = f.read()
key_file_name = "a.key"
with open(os.path.join(".", key_file_name), 'rb') as f:
key = f.read()
key = AliKeyDecryptor().decrypt(key)
iv_file_name = "a.iv"
with open(os.path.join(".", iv_file_name), 'rb') as f:
iv = f.read()
cryptor = AES.new(key, AES.MODE_CBC, iv)
result = cryptor.decrypt(video)
with open(os.path.join(".", "result.ts"), 'wb') as f:
f.write(result)
小结
本文通过阿里视频实例讲解了如何使用Chrome开发者工具分析页面数据信息和网络数据包信息。并且在此基础上使用Python实现M3U8文件下载,M3U8文件内容分析,并下载AES密钥文件,IV加密向量,和TS视频文件。最后演示了如何使用密钥文件,IV加密向量通过AES解密算法解密TS文件,并把结果保存到磁盘上。如果大家在阅读和实验的过程中有任何问题或心得,欢迎大家讨论和分享。
你好,请教一个问题,m3u8文件里的视频链接用浏览器下载到本地,通过网页下载key及iv值解密可以播放,用python抓下来,iv值就就产生了变化,导致解密后却无法播放,可是有时候又能获取到与网页相同的iv值,这是什么原因呢,我应该如何避免此类的问题呢
仔细观察规律吧,即使IV值会变,但是也是有根据的变的,有规律可循的。